Programma
- Come fa un computer a funzionare?
- Come l’hardware si interfaccia
- Gestione dei programmi
Sistema operativo
Il suo scopo principale è quello di offrire servizi agli utenti. Offre un ambiente di esecuzione facilitato alle applicazioni utente (per esempio permette di usare la ram utilizzando variabili con determinati nomi). Offre anche un ambiente grafico per l’utente.
Per fare tutto questo il sistema operativo deve comunicare con l’hardware e dare gli opportuni comandi.
Le risorse hardware più importanti sono i processori, la ram e i dispositivi di I/O.
Sistema monoprocessore
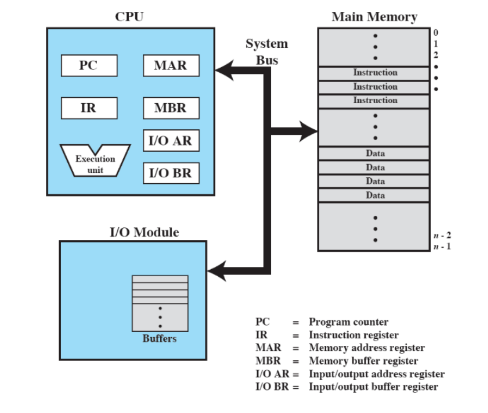
Modello di Von Neumann
Composto da tre blocchi che si possono isolare all’interno del computer.
- Processore (CPU)
- RAM
- Moduli di i/o
Questi tre blocchi devono interagire tra loro, quindi c’è un canale di comunicazione chiamato System Bus.
All’interno della CPU ci sono delle zone di memoria aggiuntive chiamate Registri.
Processore
E’ il “cervello” del computer ed è quello che si occupa di tutte le computazioni. Se c’è una computazione fatta dal computer, tipicamente è fatta dal processore.
RAM
E’ una memoria volatile (se il computer viene spento, il suo contenuto viene cancellato).
Moduli di I/O
Comprendono dispostivi di memoria secondaria non volatili, dispositivi per la comunicazione, tastiere, mouse, ecc…
Registri del processore
Sono delle zone di memoria molto più veloci di quelli della RAM.
I registri del processore sono divisibili in due categorie:
- Registri visibili dall’utente
- Registri non visibili dall’utente
Registri visibili all’utente
Sono utilizzati da chi programma in assembler o dai compilatori di linguaggi non interpretati.
Ci sono alcuni processori che hanno delle istruzioni in assembler che costringono a usare quegli registri
Altri servono per diminuire gli accessi alla RAM.
Possono condividere dati o indirizzi.
Nel caso in cui contengono indirizzi
- Possono contenere puntatori diretti
- Possono essere dei registri - indice: offset rispetto a qualche altro indirizzo
- Possono essere puntatori a segmento: se la memoria è divisa in segmenti che contengono l’indirizzo di inizio di un segmento
- Puntatori a stack: puntano all’inizio di uno stack
Registi di controllo e stato
Sono usati dal processore per controllare l’uso del processore stesso oppure sono usati da funzioni privilegiate del sistema operativo.
- Program counter: usati per istruzioni da eseguire
- Instruction register: contiene l’istruzione prelevata più di recente
- Program status word: contiene informazioni molto importanti come la disabilitazione degli interrupt
- Flag: compattati in un unico registro
Tutti questi registri vengono letti o modificati in modo implicito da opportune istruzioni assembler (esempio: un jump che modifica il pc).
Registri interni
Usati dal processore tramite microprogrammazione.
Contengono i dati da scrivere in memoria oppure forniscono lo spazio dove scrivere i dati letti dalla memoria.
Esecuzione di istruzioni
I computer sano fare solo due cose: fetch ed execute di istruzioni. Il sistema operativo si basa su questo processo.
Fetch Prende il contenuto del program counter in cui c’è un indirizzo, va in ram, prende il contenuto della cella di memoria, lo mette nell’instruction register
Execute
Il valore del pc viene incrementato (pc + 4).
Prende quello che c’è nell’intsruction register e lo esegue.
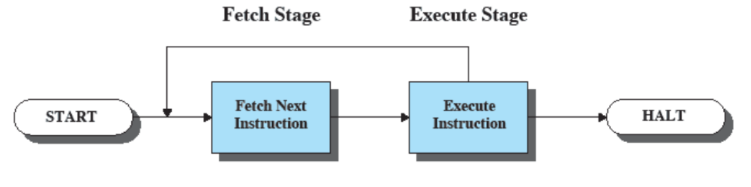
Questo processo inizia nel momento stesso in cui il computer viene acceso e si ferma quando il computer viene spento.
Categorie di istruzioni
- Scambio dati tra processore e memoria
- Scambio dati tra processore e dispositivi di I/O
- Manipolazione di dati (operazioni aritmetiche)
- Nel MIPS si possono fare solo con i registri
- Modifica del controllo (jump)
- Operazioni riservate (abilitazioni e disabilitazioni)
Come può essere eseguito un programma a un livello molto basso?
Immaginiamo di avere una macchina che ha dei registri a solo 16 bit utilizzati per memorizzare istruzioni e interi.
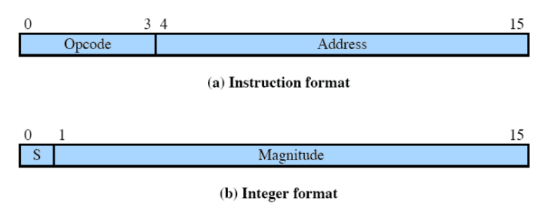
Nel caso dell’istruzione, i primi 4 bit servono per l’opcode (fa capire che istruzione è).
Nel caso dell’intero, il primo bit è il segno e il resto è il numero.
Supponiamo di conoscere 3 di questi opcode:
- (
0001 - load) e immaginiamo di dover fareload $ac from memory(prende un indirizzo nella RAM e lo mette nel registro$ac) - (
0002 - store) e immaginiamo di dover farestore $ac to memory(prende quello che c’è in$ace lo salva in memoria) - (
0101 - add) e immaginiamo di dover fareadd $ac from memory(prende$ace lo addiziona al contenuto della memoria a quell’inidirizzo e il risultato lo mette in$ac)
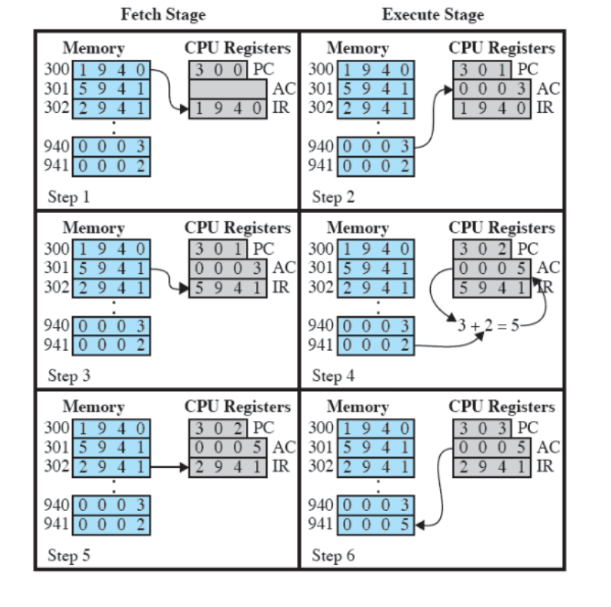
La RAM a partire dall’indirzzo 300, ha un programma di tre istruzioni (1940, 5941, 2941).
Lo scopo finale è addizionare dei numeri e metterli in un registro.
- Il pc inizialmente vale
300, la memoria carica nell’instruction register1940(fetch). Guardo l’opcode (prima cifra dell’istruzione e la converto in binario1 -> 0001, quindi faccio una load) e0003viene caricato in$ac. Il pc viene incrementato per passare all’istruzione successiva (execute). - Viene caricato
5941nell’istruction register (fetch). Guardo l’opecode (5 -> 0101, quindi faccio una add) e somma0003(contenuto in$ac) e0002. Il pc viene incrementato (execute). - Viene caricato
2941(fetch). Guardo l’opcode (2 -> 0010quindi faccio uno store) e0005viene caricato all’indirizzo941
Interruzioni
Sono il paradigma dell’interazione hardware/software. Interrompono la normale esecuzione sequenziale del processore.
Come conseguenza, viene eseguito dal software “di sistema”, che tipicamente non è stato scritto dall’utente che sta eseguendo un certo programma.
Questo software di sistema è parte del sistema operativo.
Le cause delle interruzioni sono molteplici e danno luogo a diverse classi di interruzioni:
- Da programma
- Da I/O
- Da fallimento hardware
- Da timer
Interruzioni sincrone e asincrone
Le interruzione da programma sono le uniche sincrone, cioè sono l’immediata conseguenza di una certa istruzione.
Le altre sono asincrone perché vengono sollevate molto dopo l’istruzione che le ha causate e alcune non sono neanche causate dall’esecuzione di istruzioni.
Asincrone
Si dividono in:
Interruzioni da input/output
Sono generate dal controllore di un dispositivo di I/O.7 Generalmente i dispositivi di I/O sono più lenti del processore e quindi, il processore manda un comando al dispositivo e poi aspetta che il dispositivo lo “interrompa” quando è riuscito a completare la richiesta. Infine, segnalano il completamento o l’errore di un’operazione I/O.
Interruzioni da fallimento hardware
Potrebbero non avere niente a che fare con alcune istruzioni (per esempio un’improvvisa mancanza di potenza) e quindi l’hardware manda un’interruzione.
Interruzioni da comunicazione tra CPU
Nei computer moderni spesso sono presenti più CPU e la comunicazione tra questi processori è effettuata attraverso interruzioni.
Interruzioni da timer
Sono generate da un dispositivo interno al processore (clock). Tipicamente sono usate dal sistema operativo per eseguire alcune operazioni a intervalli regolari.
Per i processori Intel, gli interrupt sono solo questi.
Interruzioni Sincrone
Sono interruzioni di programma causate da un’istruzione di programma. Per esempio:
- Overflow
- Divisione per 0
- Debugging
- Riferimento a un indirizzo di memoria momentaneamente o sbagliato o non disponibile (per esempio segmentation fault)
- Tentativo di esecuzione di un’istruzione macchina errata
- Chiamata a system call
Nei processori Intel vengono chiamate exception.
Che cosa succede esattamente?
Quando viene sollevate un’interruzione il sistema operativo crea un handler che esegue delle particolari operazioni sempre presenti nel sistema operativo.
Nel caso di interruzioni asincrone una volta terminato l’handler si riprende la normale esecuzione del programma dall’istruzione successiva a quella che ha generato l’interruzione, a meno che l’operazione non sia stata completamente abortita.
Nel caso delle interruzioni sincrone non è detto che quello descritto precedentemente accada. Si possono presentare, infatti, tre diversi casi:
- faults: errore corregibile, viene eseguita di nuovo la stessa istruzione (page fault)
- aborts: errore non corregibile, si esegue il software collegato con l’errore (segmentation fault)
- traps e system calls: si continua dall’istruzione successiva (debugging)
Ciclo fetch ed execute tenendo conto delle interruzioni
Viene eseguito il fetch normalmente. Dopo l’execute, nel caso in cui le interrupt sono abilitate, viene anche controllato se l’operazione ne genera uno oppure se ne arriva uno da un’operazione precedente, se è presente viene eseguito l’handler corrispondente.
Interrupt Handler
E’ una funzione presente nel sistema operativo e non prevista nel codice scritto dallo sviluppatore.
Quando viene eseguito, il sistema operativo e l’hardware comunicano per memorizzare il program counter e il registro di stato in modo da poter tornare successivamente (se possibile).
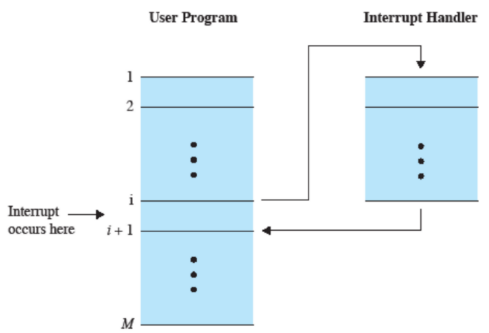
Cosa succede esattamente?
Hardware
- Un dispositivo solleva un’interruzione
- Il processore finisce l’esecuzione dell’istruzione corrente
- Segnala che “è a conoscenza” dell’interruzione
- Salva alcune informazioni, PSW (registri di controllo) e PC, nel Control Stack
- Carica nel PC il valore per eseguire le istruzione dell’handler
Software
- Salva tutti i registri della CPU in un opportuno stack
- Esegue le opportune istruzioni
- Prende i registri salvati in memoria e li sposta negli opportuni registri di appartenenza
- Riporta al valore originario PSW e PC
E’ possibile anche “spegnere” gli interrupt per togliere la fase di controllo di questi dalla CPU (vengono sollevati e non gestiti).
Ci posso anche essere interrupt annidati per cui l’harduware forza il sequenziamento.
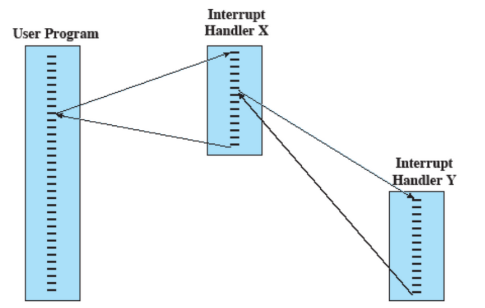
I/O con interrupt
I controller per i dispositivi I/O sono più lenti del processore e vengono gestiti tramite interrupt. Inizialmente venivano gestiti in modo sequenziale, quindi quando c’era bisogno di un dispositivo esterno, il processore non svolgeva altre operazioni e aspettava che il dispositivo fosse pronto.
Come vengono gestiti adesso?
- La CPU manda un avviso al dispositivo e nel frattempo (mentre il dispositivo di prepara) continua altri processi
- Quando il dispositivo è pronto, viene mandato un interrupt in modo tale da fa capire alla CPU che quel dispositivo può essere usato.
Warning
Il dato prima di andare in memoria deve passare per la CPU. La copia dei dati, quindi, rallenta questo metodo.
In alcuni casi questo metodo presenta delle attese:
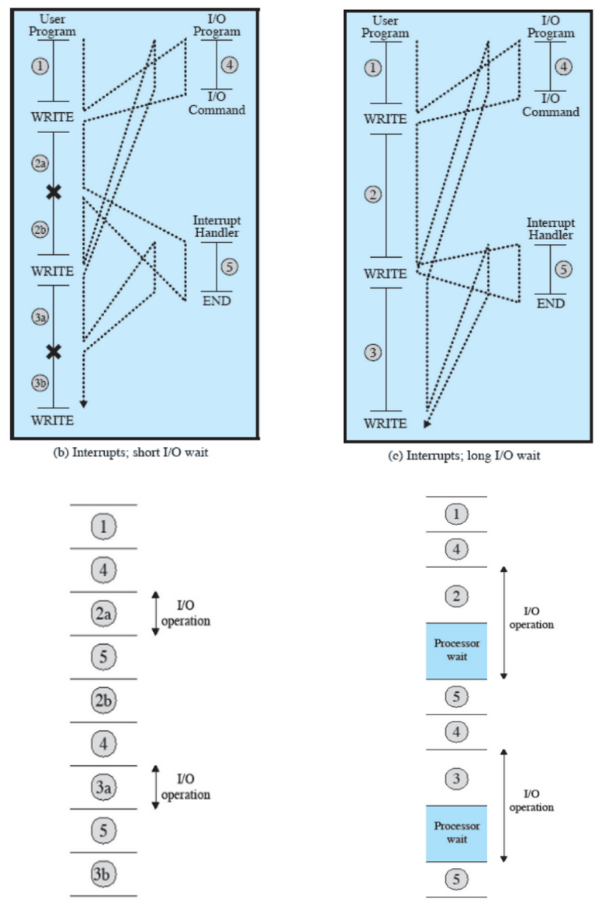
Nel caso non ci sono attese dato che, tra una scrittura e l’altra, il dispositivo è pronto e le completa.
Nel caso , la prima scrittura non è finita e intanto ne viene inviata una seconda. In questo caso, il processore deve aspettare che finisca la prima.
Accesso diretto alla memoria (DMA)
Le istruzioni di I/O tipicamente richiedono di trasferire informazioni tra dispositivo di I/O e memoria.
Con questo metodo i dispositivi I/O non hanno bisogno della CPU come tramite, ma possono entrare direttamente in memoria. Quindi vengono utilizzati comunque gli interrupt, ma una volta che arrivano alla CPU, quest’ultima non deve gestire nulla perché il trasferimento è già finito.
Trasferisce un blocco di dati direttamente dalla/alla memoria Un’interruzione viene mandata quando il trasferimento è completo.
Multiprogrammazione
Per riempire le attese inutili, il processore deve eseguire più programmi contemporaneamente.
La sequenza con cui i programmi sono eseguiti dipende dalla loro priorità e dal fatto che siano o meno in attesa di input/output.
Alla fine della gestione di un’interruzione, il controllo potrebbe non tornare al programma che era in esecuzione al momento dell’interruzione.
Gerarchia della memoria
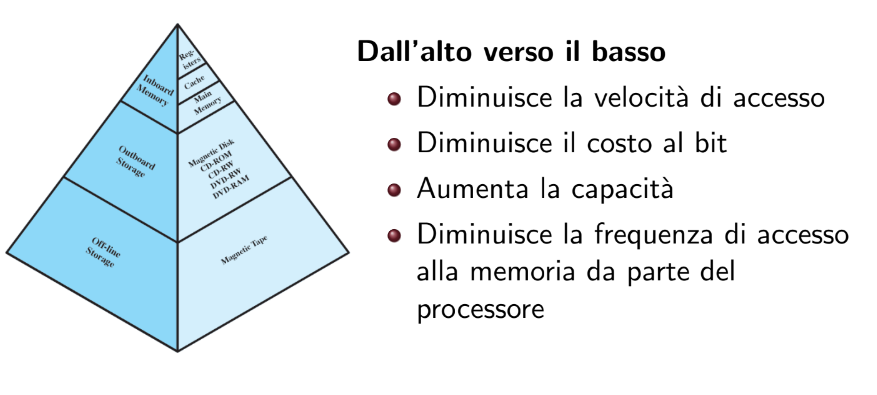
- Inboard memory: si trova sui componenti interni del Computer e ne fanno parte Registri, Cache e Ram. Tutte queste memorie sono volatili
- Outboard Memory: sono per esempio i dispositivi di memoria esterni
- Off-line Storage: sono dispositivi scollegati dal computer stesso
Memoria cache
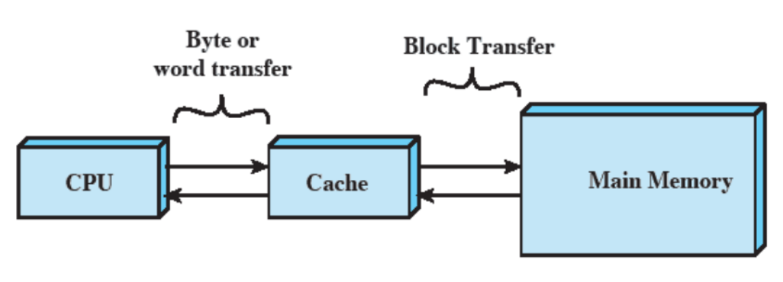
La cache contiene alcune porzioni della RAM. La CPU prima di prendere un dato dalla RAM, controlla se è presente nella Cache. Se il dato non è presente, lo prende in RAM e scrive quella porzione nella Cache (questo accade perché è molto probabile che quel dato verrà riutilizzato dopo poco - si parla, quindi, di località dei riferimenti).
La Cache è invisibile ai programmatori e al compilatore. Nemmeno il sistema operativo vede la Cache, nonostante possa decidere di non usarla. Alcune parti del sistema operativo, inoltre, imitano il funzionamento della Cache stessa.
La Cache è quindi gestita completamente dall’Hardware tramite dei circuiti.
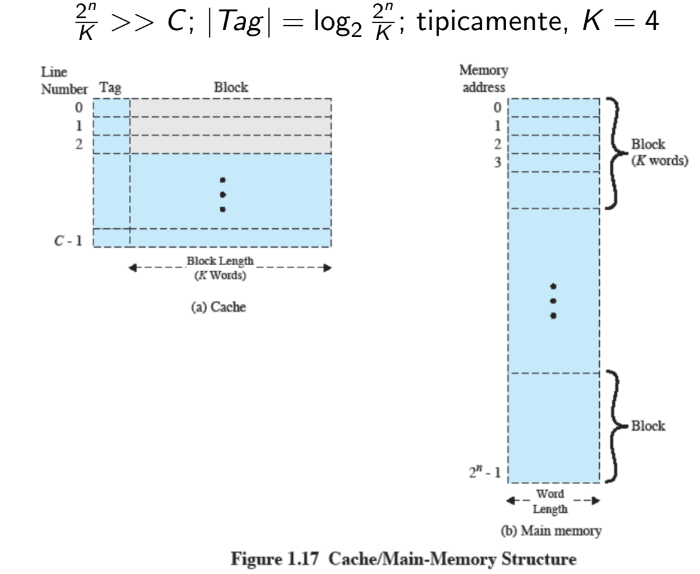
Quindi date locazioni di memoria RAM le dividiamo per , ovvero il numero di word in un blocco e otteniamo un numero molto più grande rispetto alla grandezza C della cache.
Il tag quindi deve essere grande a sufficienza per coprire tutti i blocchi.
Schema funzionamento
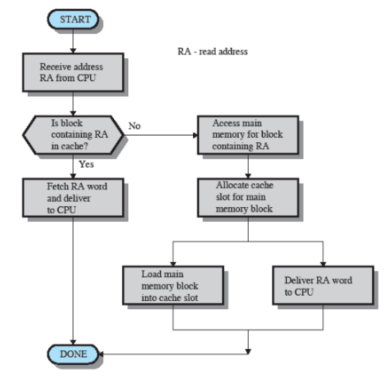
- Capacità della Cache: Anche con cache molto piccole diminuiamo di molto gli accessi in RAM.
- Ma c’è da considerare anche la grandezza dei blocchi: Con blocchi molto grandi ho molte possibilità di trovare i dati in cache ma incrementarli troppo è controproducente infatti saranno di più anche i dati da sovrascrivere quando non troviamo qualche dato
Dobbiamo, quindi, trovare un giusto equilibrio.
Notazioni sulla Cache
- Funzione di mappatura: determina in che locazione della cache va messo un determinato blocco di memoria.
- Algoritmo di rimpiazzamento: determina in che modo scegliere quale blocco va rimpiazzato in caso serva, tipicamente si usa l’algoritmo LRU (least recently used) che rimpiazza il blocco usato meno recentemente, ovvero il più vecchio presente in Cache
- Politica di scrittura: quando si vuole scrivere un dato in RAM si possono usare più strade. Per esempio, se il dato è stato scritto in Cache, verrà scritto anche in RAM? Se si, stiamo usando il Write-Through. Quindi ogni modifica che avviene in Cache avviene anche in RAM. Altrimenti viene usato il Write-Back, cioè il dato viene scritto in Cache ma non in RAM perché se successivamente dobbiamo leggerlo, verrà letto dalla Cache e quindi non c’è bisogno di averlo in RAM. Lo scriviamo solo in caso di rimpiazzi su quel blocco, altrimenti perdiamo solo lo stato aggiornato. In questo modo la memoria potrebbe trovarsi in uno stato “obsoleto” ma è sicuramente più efficiente del write-trough
Esempio

Il processore ha più processori interni e ogni processore ha diverse cache. Salendo di numero diventano più grandi e più lente, quindi si controlla in ordine .
- sono due cache, una per istruzione e un’altra per il resto dei dati.
- e sono sempre 2 ciascuna ma contengono qualsiasi tipo di dato
Come detto prima il S.O. può spegnere il caching e inoltre può decidere la politica di scrittura, ad esempio Linux non la spegne mai e utilizza sempre write-back.
Strati e utenti
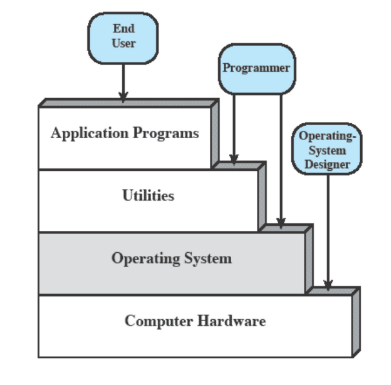
Quali sono i servizi offerti da un sistema operativo?
- Esecuzioni di programmi anche in contemporanea
- Accesso ai dispositivi di I/O
- Accesso al sistema operativo stesso attraverso uno shell
- Sviluppo di programmi
- Rilevamento e reazione ad errori hardware/software
- Accounting: una collezione di statistiche di sistema e monitoraggio delle risorse che viene utilizzato per capire cosa migliorare
Quindi il SO è un programma che gestisce il funzionamento degli altri programmi, prepara i loro ambienti, li manda in esecuzione, gestisce errori. E’ un’interfaccia tra hardware e software.
Cos'è il Kernel?
E’ una parte di sistema operativo in codice macchina che è racchiusa tutta insieme in una parte della RAM (solitamente quella iniziale) e serve appunto per eseguirlo.
Evoluzione dei sistemi operativi
I sistemi operativi esistevano già dagli anni 40’ ed erano molto diversi rispetto a quelli di adesso.
L’evoluzione è dovuta principalmente a:
- Aggiornamenti Hardware
- Nuovi servizi
- Correzione di errori
Anni ‘40
Non c’era nessun Sistema Operativo e per fornire comandi a un computer si usavano delle console con interruttori. I computer arrivavano a occupare intere stanze.
Il metodo in Input venne presto migliorato grazie alle schede perforate:
Anni ‘50/’60
Si mettono insieme più programmi da eseguire, che presero il nome di jobs e il sistema operativo serviva a gestire questi ultimi. Questo metodo funzionava molto bene in sistema non interattivi (batch), poiché il sistema richiedeva un dato input e l’utente doveva solo aspettare la fine dei calcoli.
Quali erano le problematiche di questo sistema?
- Protezione della memoria: per esempio se un job andava a scrivere nella zona della memoria del controllore dei jobs, questa parte non doveva essere accessibile.
- Timer: impedisce che un job blocchi l’intero sistema per essere eseguito. Infatti, alcuni di questi impiegavano giorni per essere eseguiti.
- Istruzioni privilegiate: Per esempio, il sistema di controllo dei jobs doveva essere eseguito con dei privilegi più alti. Infatti, il sistema può accedere a quella zona di memoria.
Quindi i job venivano eseguiti in modalità utente (numero limitato di istruzioni) mentre il monitor dei job in modalità sistema (possono essere eseguite più istruzioni e possiamo accedere a zone di memoria protette).
C'era un problema molto importante
Più del 96% del tempo è sprecato ad aspettare i dispositivi di I/Où

Come possiamo vedere, di quei 31 millisecondi, solo 1 è lavoro effettivo della CPU. Gli altri sono attesa di I/O.
Quindi prima veniva eseguita una programmazione singola, cioè un’operazione per volta con tante attese.
Per questo motivo si passò alla multiprogrammazione.
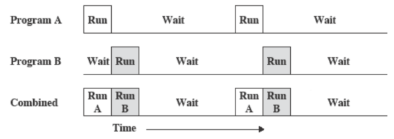
Più programmi in esecuzione e contemporaneamente all’attesa di uno, ne viene svolto un altro (minori tempi di attesa).
Esempio
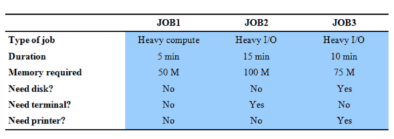
Prendiamo questi 3 jobs. Il primo è molto incentrato sulla CPU e dura 5 minuti, mentre gli altri due utilizzano molto I/O e durano 15 e 10 minuti.
Cosa succede in entrambi i tipi di programmazione?
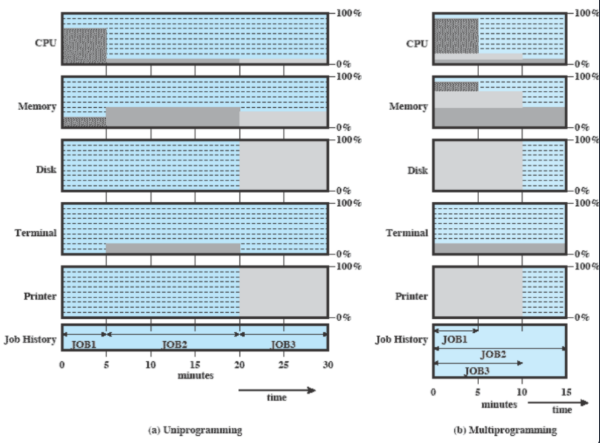
A sinistra abbiamo programmazione singola e quindi si impiegano 30 minuti (1 job dietro l’altro) e un utilizzo non gestito molto bene delle risorse.
Nella multi programmazione invece eseguiamo tutti i job insieme, infatti job1 utilizza solo CPU e nessun dispositivo, mentre gli altri 2 utilizzano dispositivi diversi e quindi possono essere eseguiti tutti contemporaneamente.
Come statistiche otteniamo:

Throughput: Mean Response Time: Media dei tempi di completamento. Nel caso di uniprogramming dobbiamo considerare che e quindi .