Reti
Info
Le reti vengono utilizzate attraverso dispositivi chiamati nodi. Questi nodi sono collegati tramite link. Quando un nodo ospita un’applicazione, viene definito host. In caso contrario, si parla di router o switch.
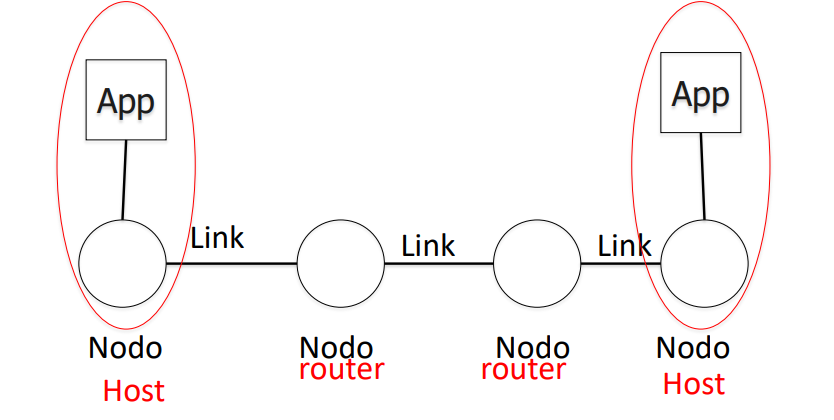
Sistemi terminali e dispositivi di interconnessione
Una rete è composta da due principali categorie di dispositivi:
- Sistemi terminali: dispositivi che si scambiano informazioni.
- Dispositivi di interconnessione: dispositivi che gestiscono la trasmissione dei dati tra i vari nodi.
Sistemi Terminali Possono essere di due tipi:
- Host: dispositivi di proprietà degli utenti, come laptop, smartphone e tablet, dedicati all’esecuzione di applicazioni.
- Server: computer ad alte prestazioni che forniscono servizi a più applicazioni utente, gestiti da amministratori di sistema.
Dispositivi di interconnessione Rigenerano/modificano ill segnale che ricevono e si distinguono in:
- Router: collegano una rete ad altre reti
- Switch: collegano più sistemi terminali all’interno di una rete locale, inoltrando i dati ai dispositivi destinati
- Modem: rigenerano i segnali e modificano la codifica dei dati
Collegamenti
I dispositivi di rete vengono collegati utilizzando collegamenti che possono essere:
Cablati
I collegamenti cablati utilizzano mezzi fisici, come il rame o la fibra ottica, in cui il segnale viaggia attraverso un cavo fisico.
Wireless
I collegamenti wireless non utilizzano cavi fisici, ma si basano su onde elettromagnetiche o segnali satellitari che viaggiano nell’aria. Questi collegamenti sono influenzati dall’ambiente di propagazione, come riflessioni, ostacoli e interferenze.
Mezzi trasmissivi cablati
- Bit: l’unità di trasmissione dei dati che viaggia da un sistema terminale all’altro, passando attraverso una serie di dispositivi trasmittenti e ricevitori
- Mezzo fisico: il materiale che connette il trasmettitore e il ricevitore
Fibra ottica E’ un mezzo sottile e flessibile che trasmette impulsi di luce. Questo tipo di collegamento ha un’alta frequenza di trasmissione che può variare da 10 a 100 Gbps ed è immune alle interferenze elettromagnetiche, con un basso tasso di errore.
Wireless
I collegamenti wireless utilizzano onde elettromagnetiche per trasmettere segnali attraverso l’aria. Sebbene non richiedano l’installazione di cavi fisici, sono influenzati dall’ambiente di propagazione che può causare riflessioni, ostruzioni o interferenze.
Classificazione delle reti
- PAN (personal area network): rete molto piccola (Bluetooth)
- LAN (local area network): rete utilizzata nelle aziende, basata su wifi e ethernet
- MAN (metropolitan area network): si estendono a livello cittadino
- WAN (wide area network): si estendono a livello nazionale
- Internet: la rete che copre tutto il pianeta
LAN
Una LAN è una rete privata che collega i sistemi terminali all’interno di un singolo edificio. Ogni dispositivo in una LAN ha un indirizzo IP univoco che lo identifica.
- LAN con cavo condiviso:
- Composta da un cavo dove è possibile collegare ogni nodo della rete (rete broadcast: quando un nodo trasmette, tutti gli altri lo ricevono).
- Solo il destinatario elabora il pacchetto, tutti gli altri lo ignorano
- La comunicazione avviene in modo sequenziale, un dispositivo per volta

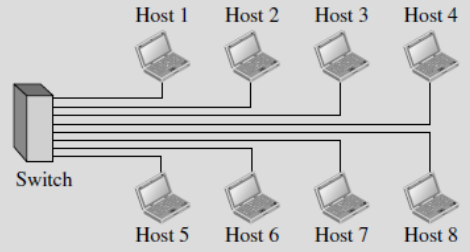
- LAN con switch (tipologia a stella):
- Ogni dispositivo in rete è direttamente collegato allo switch
- Lo switch identifica l’indirizzo di destinazione e invia il pacchetto solo al destinatario, riducendo il traffico nella rete e permettendo a più dispositivi di comunicare contemporaneamente
WAN
Una WAN copre un’area geografica estesa, come una città, una nazione o una regione, e connette vari dispositivi di rete, come router, switch e modem. Di solito è gestita da un Internet Service Provider (ISP).
Wan punto-punto

Collega due mezzi tramite un mezzo trasmissivo (wireless o cavo)
Wan a commutazione
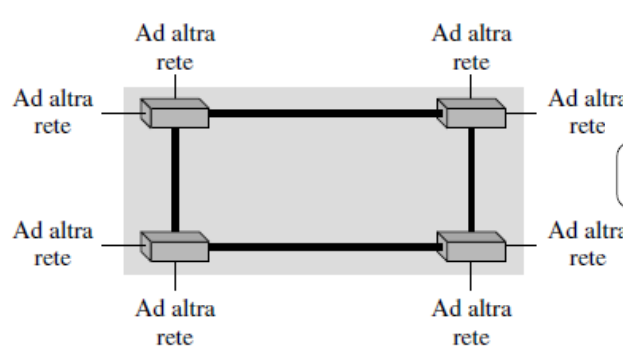
WAN più grandi che ha più di due punti di terminazione, viene utilizzata nelle dorsali di internet.
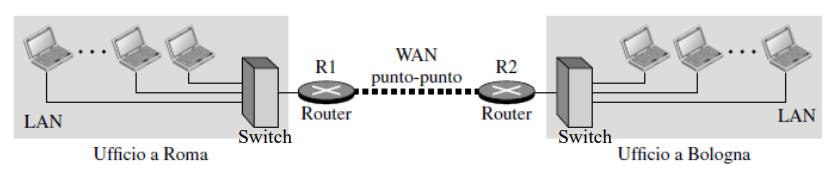
Internetwork composta da due LAN e una WAN punto-punto
Un’internetwork è una combinazione di LAN e WAN collegate tra loro. Ad esempio, un’azienda con uffici in due città può affittare una WAN punto-punto per connettere le due LAN, creando una internetwork. I router sono utilizzati per instradare i pacchetti tra le LAN.
Rete del GARR Il GARR è una WAN nazionale che collega centri culturali, come università e biblioteche. Si tratta di un’infrastruttura in fibra ottica che si estende per circa 15.000 km, utilizzando le tecnologie di commutazione più avanzate.
Commutazione (switching)
Una internetwork è una rete composta da dispositivi (come switch e router) che scambiano informazioni tra loro. Esistono due principali modalità di commutazione:
Reti a commutazione di circuito
Tra destinatario e trasmittente viene stabilito un collegamento (circuito) che viene usato per l’intera comunicazione finché non è terminata, come succede per esempio con il sistema telefonico.
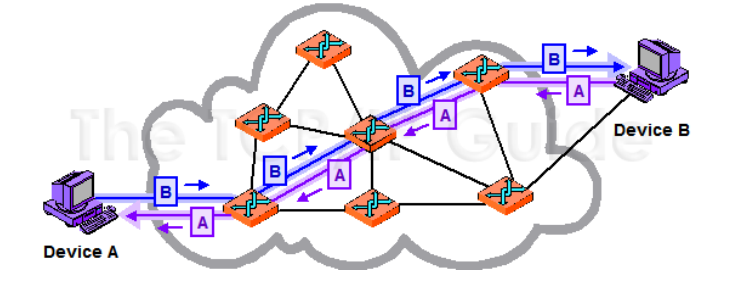
Tra i due host ci sono diversi possibili percorsi. Vengono riservate le risorse lungo il percorso e ogni dato seguirà quel percorso fino alla fine della comunicazione.
Esempio
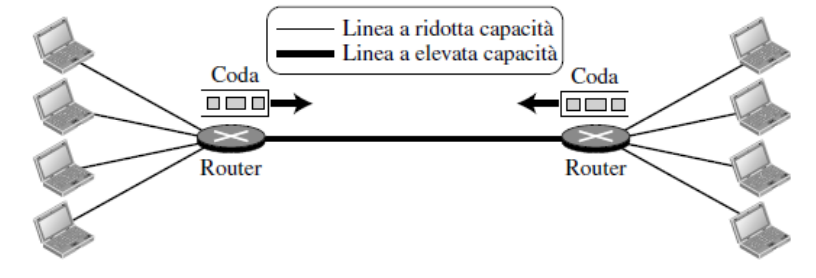
La linea tra due switch può gestire contemporaneamente quattro canali voce (condivisa tra tutte le coppie di apparecchi telefonici)
Quando tutte e 4 persone da un lato comunicano con le altre 4 persone dall’altro lato si avrà che la capacità della linea è completamente utilizzata.
Quando solo una persona da un lato è collegata con una persona dall’altro lato, viene utilizzato solo 1/4 della capacità
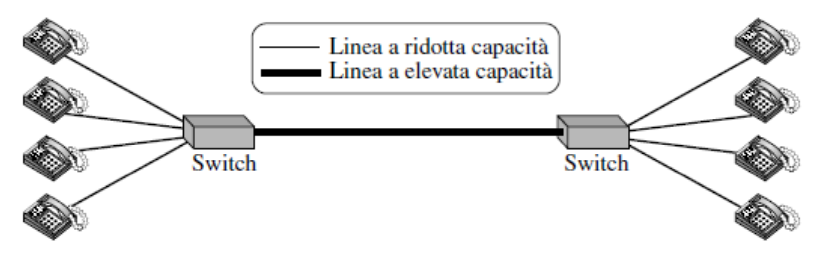
In questo caso, le risorse di rete, come l’ampiezza di banda, vengono suddivise in “pezzi” assegnando una porzione per ogni comunicazione. Se una comunicazione non è attiva, la risorsa rimane inutilizzata.
Reti a commutazione di pacchetto
Nella commutazione di pacchetto, i dati vengono suddivisi in pacchetti di dimensione fissa. Ogni pacchetto è indipendente dagli altri e viene inviato attraverso il percorso migliore disponibile in ogni momento. Non vengono riservate risorse per la comunicazione e i pacchetti possono seguire percorsi diversi e arrivare a destinazione in ordine diverso.
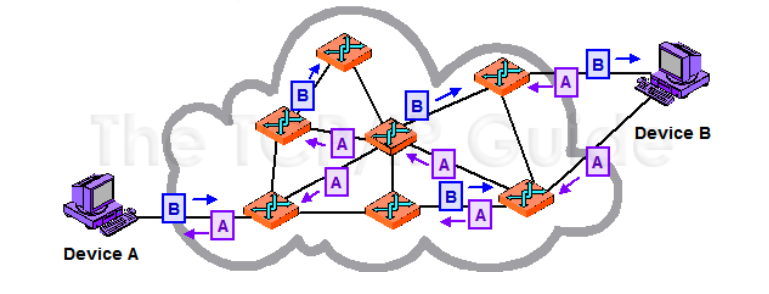
Internet
Internet è una rete a commutazione di pacchetto.
Quando due dispositivi comunicano, non c’è alcun ritardo per i pacchetti. Tuttavia, se più dispositivi sono in comunicazione e la capacità della rete non è sufficiente per gestire tutti i pacchetti in arrivo, i pacchetti possono subire ritardi. Ogni pacchetto può essere memorizzato in una coda dai router.
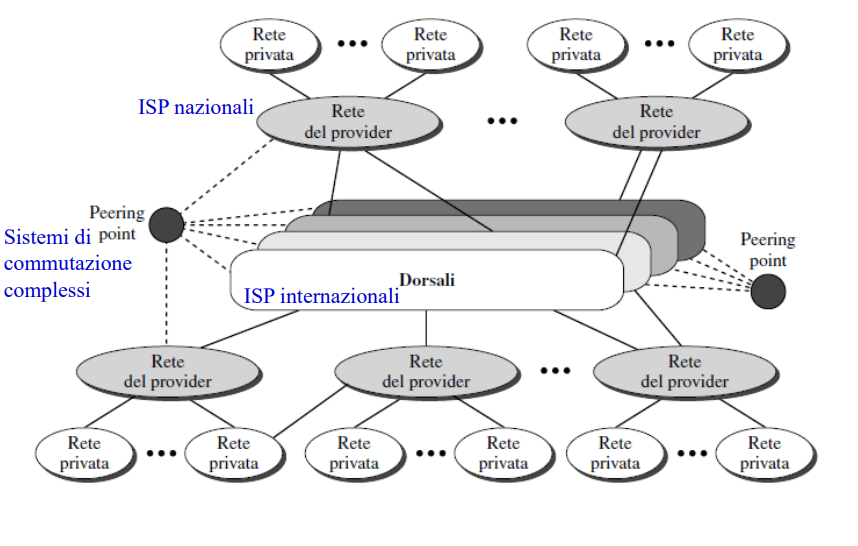
Concettualmente, Internet ha tre livelli:
- Dorsali: la rete principale di Internet
- Rete del provider: la rete che collega i provider locali alla dorsale
- Rete privata: la rete dell’utente finale, che si collega a Internet tramite un ISP
Accesso a Internet
Per accedere a Internet, un utente deve essere fisicamente collegato a un ISP, di solito tramite una WAN punto-punto. Il collegamento che connette l’utente al primo router di Internet è chiamato rete di accesso.
Tipologie di Accesso
- Accesso tramite rete telefonica: utilizzando tecnologie come DSL o dial-up
- Accesso tramite reti wireless: come Wi-Fi o rete cellulare
- Accesso diretto: tramite un collegamento fisico, come un cavo Ethernet
Accesso via rete telefonica
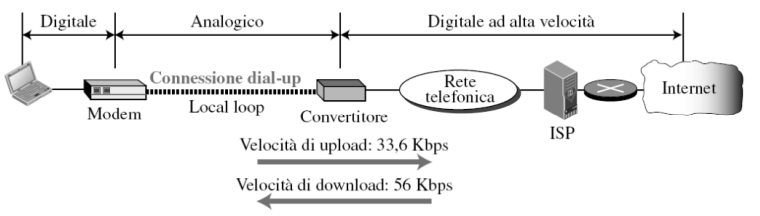
E’ possibile collegarsi a Internet utilizzando la linea telefonica tra la sede del dispositivo e la centrale telefonica con una WAN punto-punto.
Servizio dial-up Viene inserito un modem (modulatore-demodulatore) nella linea telefonica, che converte i dati digitali in analogici e viceversa. I problemi più grandi legati a questo tipo di rete sono la lentezza e l’impossibilità di parlare e navigare contemporaneamente.
Servizio DSL (digital subscriber line) Questa tecnologia supporta velocità più elevate sulla linea telefonica e divide il collegamento tra abitazione e ISP in tre bande di frequenza non sovrapposte, permette navigazione e telefonate nello stesso momento.
Accesso tramite Ethernet Ci si collega col proprio terminale direttamente allo switch tramite cavo, lo switch è poi collegato ad un router che a sua volta è connesso ai router della dorsale.
Accesso Wireless Ci colleghiamo tramite WiFi all’access point locale collegate ai vari router, ha ovviamente un raggio d’azione limitato. Oppure possiamo utilizzare la rete cellulare che si basa sugli access point della compagnia telefonica, hanno raggi di azioni molto più elevati rispetto ai classici accesso point WiFi.
Un pacchetto (un blocco di dati generati da un host) dovrà passare in diversi ISP. Uno dei problemi principali è trovare il percorso che il pacchetto dovrà trovare dalla sorgente al destinatario (routing).
Capacità e prestazioni delle reti
Velocità significa quanto la rete riesce a trasmettere velocemente i dati.
Info
Il concetto di velocità di una rete comprende molti fattori:
- Ampiezza di banda
- bitrate
- throughput
- ritardi
- perdita di pacchetti
Bandwidth o ampiezza di banda Con questo termine, si intendono due concetti legati tra loro.
-
Caratterizzazione del mezzo trasmissivo: misura la larghezza dell’intervallo di frequenze utilizzate nel sistema trasmissivo (Hz). Più è ampia, più è la quantità di informazione che posso trasmettere.
-
Caratterizzazione di un collegamento: misura la quantità di bit al secondo che un link garantisce di trasmettere (bps)
Il bit rate è la quantità di bit al secondo che un link può trasmettere (immettere sul canale). Il bit rate dipende dalla banda ed è proporzionale a essa.
Esempio
Il rate di un link Fast Ethernet è di 100 Mbps, ovvero tale rete può inviare al massimo 100 Mbps
Throughput
Indica quanto effettivamente la rete è in grado di inviare i dati.
E’ misurato come il rate (bps), ma tipicamente è <= al rate, questo perché il rate è la misura della potenziale velocità di un link.
Esempio
Una strada è progettata per far transitare 1000 auto al minuto da un punto all’altro. Se c’è traffico, tale cifra può essere ridotta a 100. Il rate è 1000 auto al minuto, il throughput 100 auto al minuto
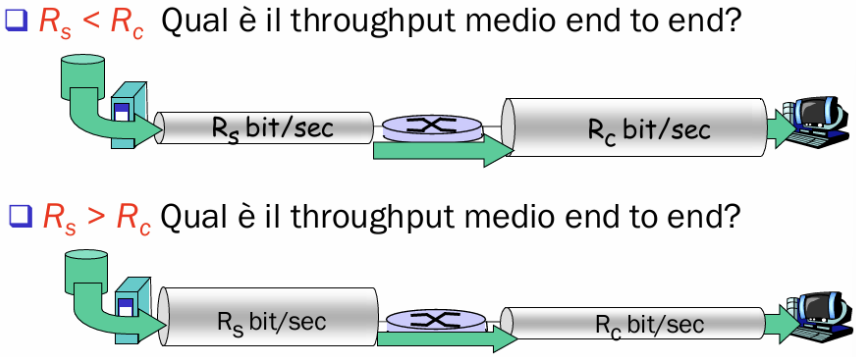
Come facciamo a misurare il throughputffff end-to-end (dalla sorgete alla destinazione)?
Dato che il throughput è definito da .
In generale il throughput è dato dal minimo dei throughput dei collegamenti che formano il percorso.
Latenze e perdite di pacchetti
Definizione
La latenza è il tempo che un pacchetto impiega ad arrivare a destinazione dal momento in cui il primo bit parte dalla sorgente.
Nella commutazione di pacchetto, i pacchetti si accumulano nei buffer dei router. Se il tasso di arrivo dei pacchetti sul collegamento è maggiore rispetto al rate del collegamento, i pacchetti si accoderanno in attesa del loro turno e quindi si genera un ritardo. Se nel buffer non c’è più spazio per altri pacchetti, allora questi verranno scartati.
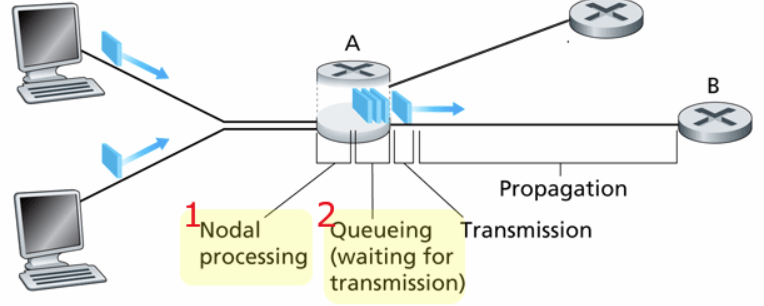
Esistono 4 tipi di cause di ritardo dei pacchetti:
- Ritardo di elaborazione
- Ritardo di accodamento
- Ritardo di trasmissione
- Ritardo di propagazione
Ritardo di elaborazione Ogni pacchetto viene processato controllando eventuali errori sui bit e in caso, vengono scartati. Infine, viene determinato il canale di uscita.
Ritardo di accodamento Equivale all’attesa di trasmissione nella coda di input e nella coda di output del router. Varia in base al livello di congestione del router e da pacchetto a pacchetto.
Il calcolo si basa su misurare statistiche e dipende dall’intensità di traffico:
Dove:
- è il rate di trasmissione ()
- è la lunghezza del pacchetto ()
- è il tasso medio di arrivo dei pacchetti ()
Ritardo di trasmissione Indica il tempo richiesto per immettere tutti i bit del pacchetto sul collegamento.
Supponiamo che il primo bit venga trasmesso al tempo e l’ultimo al tempo . Il ritardo di trasmissione sarà .
Possiamo calcolarlo anche in questo modo:
Ritardo di propagazione Tempo che impiega un bit per propagarsi sul canale (viaggiare da un punto a un punto ). Lo calcoliamo come:
Osservazione
La velocità di propagazione corrisponde alla velocità della luce ()
Ritardo di nodo
Il ritardo quindi è dato da:
Dove:
- è il ritardo di trasmissione che è significativo sui collegamenti a bassa velocità
- è il ritardo di propagazione che va da pochi microsecondi a centinaia di millisecondi
- è il ritardo di elaborazione, in genere pochi microsecondi o meno
- è il ritardo di accodamento che dipende dalla congestione della rete in quel momento
Perdita dei pacchetti
Se una coda (detta anche buffer) ha capacità finita, quando il pacchetto trova la coda piena, viene scartato (quindi va perso). Il pacchetto perso può essere ritrasmesso dal nodo precedente, dal sistema terminale che lo ha generato o non essere ritrasmesso affatto
Ritardi e percorsi in Internet
Traceroute o tracert E’ un programma diagnostico che fornisce una misura del ritardo dalla sorgente a tutti i router lungo il percorso Internet punto-punto verso la destinazione. Invia gruppi di tre pacchetti (ogni gruppo con un tempo di vita incrementale) che raggiungeranno il router sul percorso verso la destinazione. Il router restituirà i pacchetti al mittente e calcolerà l’intervallo tra trasmissione e risposta.
L’output presenta 6 colonne:
- Il numero di router sulla rotta
- Nome del router
- Indirizzo del router
- tempo di andata e ritorno 1°pacchetto
- tempo di andata e ritorno 2°pacchetto
- tempo di andata e ritorno 3°pacchetto
Il round trip time include i 4 ritardi e può succedere (in caso di congestione) che i pacchetti prendano percorsi diversi. Se la sorgente non riceve risposta da un router intermedio (o ne riceve meno di 3) allora pone un asterisco al posto del tempo RTT.
Prodotto rate * ritardo
Indica il numero massimo di bit che possono riempire il collegamento. Supponiamo di avere un link da e un ritardo di contemporaneamente sul link:
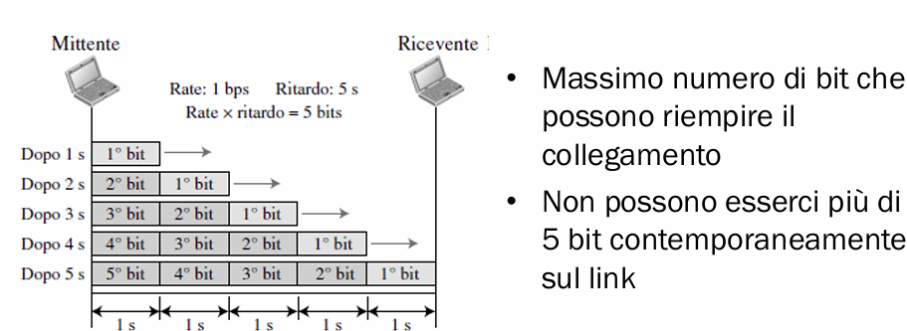
Il primo bit entra dopo un secondo e dopo 5 secondi sarà arrivato alla fine. In questi 5 secondi saranno entrati altri bit, a differenza di un secondo per via del bitrate, e si saranno mossi tutti ogni secondo.
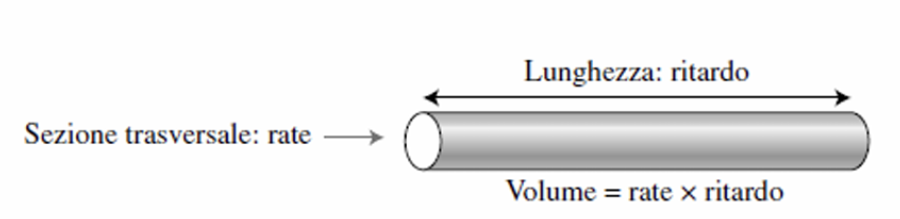
Possiamo pensare al link come un tubo in cui la sezione trasversale indica il rate e la lunghezza il ritardo. Possiamo, quindi, vedere il volume come prodotto tra rate e ritardo:
Stack protocollare
Non è sufficiente collegare router e cavi per usare la reti, infatti hardware e software devono interagire.
Protocollo
Un protocollo definisce le regole che il mittente e il destinatario, così come tutti i sistemi intermedi coinvolti, devono rispettare per essere in grado di comunicare.
Strutturazione a livelli
La strutturazione dei protocolli in livelli permette di suddividere compiti complessi in parti più semplici e gestibili.
Modularizzazione e indipendenza dei livelli Ogni livello può essere visto come un modulo che funge da “black box”, in cui ci si concentra solo sugli ingressi e sulle uscite, senza preoccuparsi di come i dati vengano effettivamente trasformati al suo interno.
Se due dispositivi producono lo stesso output dato lo stesso input, possono essere considerati equivalenti. Questo significa che le macchine possono provenire da fornitori diversi senza compromettere il funzionamento del sistema.
Inoltre, c’è una chiara separazione tra i servizi e la loro implementazione: ogni livello sfrutta i servizi offerti dal livello inferiore e offre, a sua volta, servizi al livello superiore, indipendentemente dal modo in cui questi servizi sono implementati.
Stack protocollare TCP/IP e gerarchia dei protocolli
Il modello TCP/IP è una famiglia di protocolli utilizzata su Internet, strutturata come una gerarchia di moduli che interagiscono tra loro, ognuno dei quali offre funzionalità specifiche.
Il termine “gerarchia” indica che ogni protocollo di livello superiore si basa sui servizi forniti dai protocolli di livello inferiore.
Oggi il modello TCP/IP è generalmente descritto come composto da cinque livelli:
- Applicazione: rappresenta il livello più vicino all’utente, dove operano le applicazioni di rete (come HTTP, SMTP, FTP, DNS). Qui i pacchetti sono chiamati messaggi.
- Trasporto: si occupa di trasferire i messaggi tra il client e il server di un’applicazione. Usa protocolli come TCP (affidabile) e UDP (non affidabile). I pacchetti in questo livello sono chiamati segmenti.
- Rete: gestisce l’instradamento dei segmenti dalla sorgente alla destinazione. I pacchetti sono chiamati datagrammi.
- Link (collegamento): si occupa della trasmissione dei datagrammi da un nodo all’altro lungo il percorso (ad esempio, Ethernet, Wi-Fi, PPP). I pacchetti in questo livello sono chiamati frame.
- Fisico: si occupa del trasferimento dei singoli bit lungo il canale di comunicazione.
Dove si trova lo stack protocollare? In qualsiasi dispositivo connesso alla rete. I router implementano solo una parte dello stack protocollare.
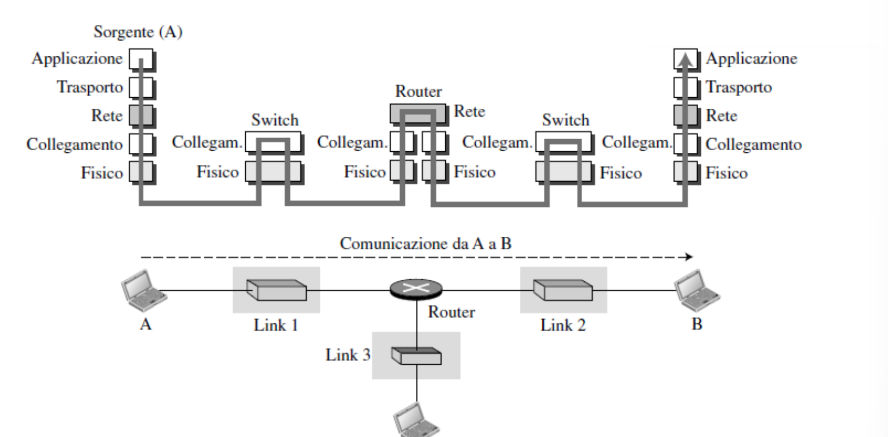
La rete, quindi, è organizzata in layer messi l’uno sopra l’altro, con lo scopo di offrire servizi agli strati superiori nascondendo i dettagli implementativi. Un layer di un computer quindi deve essere in comunicazione con il layer di un altro computer, ma non direttamente fra loro due. Infatti, dovranno passare fra gli altri layer. Il come comunicano viene definito dai protocolli.
Le entità che formano questi strati prendono il nome di peer. Quindi, per esempio, due layer di collegamento formano un peer.
Differenza tra servizi e protocolli
Servizio: insieme di primitive che uno strato offre a quello superiore, definisce quindi quali operazioni si possono usare ma non il come ovvero l’implementazione.
Protocollo: è un insieme di regole che controllano il formato e significato dei pacchetti o in generale i messaggi che vengono scambiati all’interno dello strato
Incapsulamento e decapsulamento
Quando un pacchetto parte dal livello applicazione e scende verso il basso, viene incapsulato. Quindi viene inserito in un “contenitore” con delle informazioni aggiuntive. Il router è il dispositivo che effettua sia incapsulamento che decapsulamento dato che è collegato a due link.
Aggiungendo questi header permettiamo ad ogni livello di riconoscere su quali pacchetti devono agire.
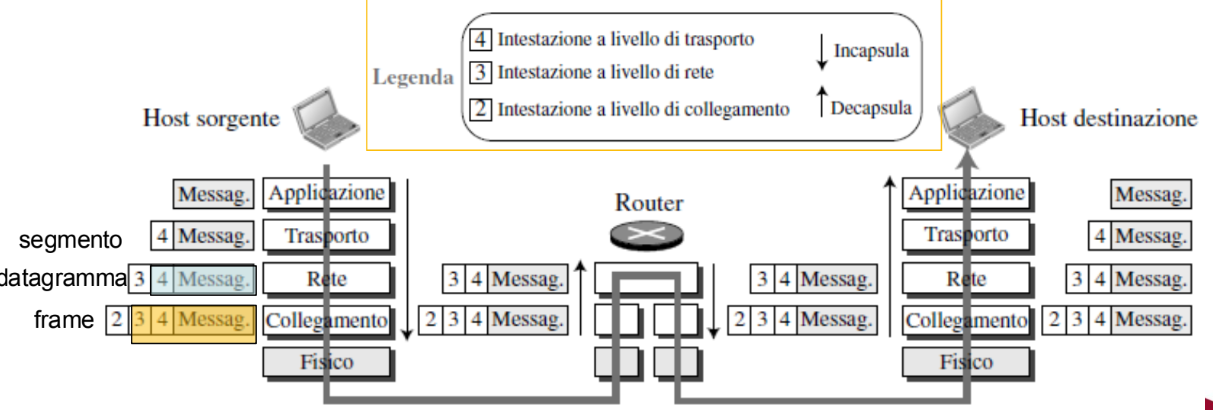
I nomi che diamo ai pacchetti nei vari livelli dipendono quindi dall’header presente:
- Messaggio: nessuna intestazione
- Segmento o datagramma utente: header trasporto + messaggio
- Datagramma: header rete + segmento
- Frame: header collegamento + datagramma
Quando il frame viaggia attraverso la rete e arriva all’host di destinazione, andrà a decapsulare il frame a ogni livello.
Multiplexing e demultiplexing
Dato che lo stack protocollare TCP/IP prevede più protocolli nello stesso livello, è necessario eseguire il multiplexing alla sorgente e il demultiplexing alla destinazione
- Multiplexing: un protocollo può incapsulare (uno alla volta) i pacchetti ottenuti da più protocolli del livello superiore
- Demultiplexing: un protocollo può decapsulare e consegnare i pacchetti a più protocolli del livello superiore
E’ necessario un campo nel proprio header per identificare a quale protocollo appartengano i pacchetti incapsulati
Vantaggi e svantaggi della modularità
Tra i vantaggi del modello, troviamo la modularità, che garantisce una maggiore facilità nel design e nella gestione del sistema, permettendo anche di modificare un modulo senza influenzare gli altri.
Tuttavia, uno degli svantaggi è che, in alcuni casi, potrebbe essere necessario scambiare informazioni tra livelli non adiacenti. In questi casi, si verrebbe a violare il principio della stratificazione, che prevede che i livelli comunichino solo con quelli immediatamente superiori o inferiori.
Modello OSI
L’ISO (International Organization for Standardization) ha definito il modello OSI come modello alternativo al TCP/IP. E’ composto da 7 livelli:
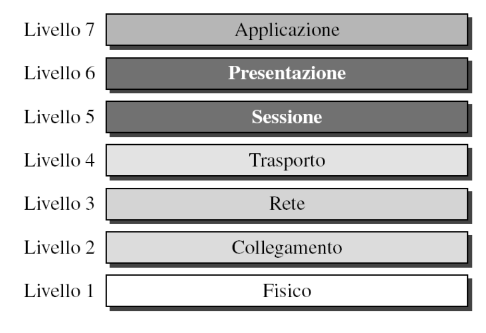
Fondamentalmente aggiunge due livelli al modello TCP/IP tra il livello applicazione e trasporto (livello presentazione e sessione).
Il modello OSI non è mai stato implementato perché:
- Molte infrastrutture usavano già il modello TCP/IP e fare un cambio avrebbe comportato troppi costi.
- Per alcuni livelli è stata fornita poca documentazione e quindi non sono mai stati creati software appositi
- Non furono mai state dimostrate delle prestazioni così migliori da convincere le aziende a sostituire il TCP/IP
Livello applicazione
Qui, la comunicazione è fornita per mezzo di una connessione logica: questo significa che i livelli applicazione, nei due lati della comunicazione, agiscono come se esistesse un collegamento diretto attraverso il quale poter inviare e ricevere messaggi.
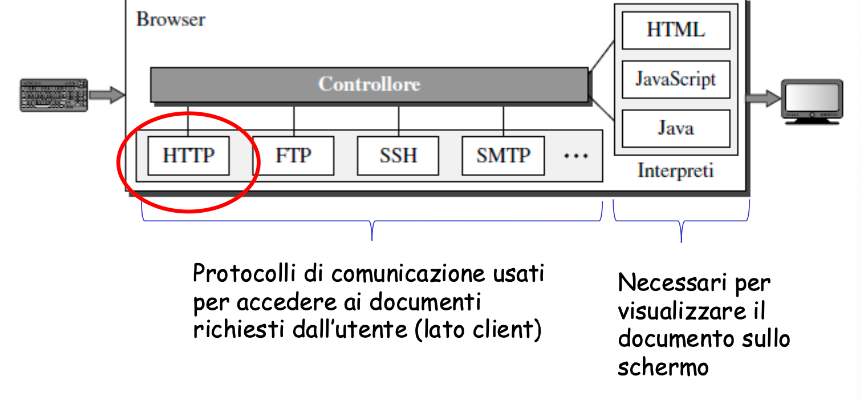
Web e HTTP
Il www (World Wide Web) è un’applicazione nata dalla necessità di scambio e condivisione di informazioni tra ricercatori universitari di varie nazioni.
Opera su richiesta (on demand) ed è facile rendere informazioni disponibili. Ad oggi ci sono diversi browser e motori di ricerca per la ricerca di informazioni.
Da un lato abbiamo il browser (web client). Nel momento in cui cerchiamo un sito, parte la richiesta alla pagina web e arriva al web server. Dal web server ci arriva la pagina web che stiamo cercando.
Componenti applicazione web:
- Web client: interfaccia con l’utente
- Web server (ex. Apache)
- HTML: linguaggio standard per pagine web
- HTTP: protocollo per la comunicazione tra client e server Web
HTTP
Terminologia
Una pagina web è:
- costituita da oggetti (immagini, file html. ecc…)
- formata da un file base html che include diversi oggetti referenziati
Inoltre, ogni oggetto è referenziato da un URL (uniform resource locator)
Gli URL sono composti da 3 parti:
- Il protocollo
- Nome della macchina in cui è situata la pagina
- Il percorso del file che indica la pagina, il nome del file e la posizione nel filesystem

Documenti web Ci sono 3 categorie:
- Statico: contenuto predeterminato memorizzato sul server
- Dinamico: creato dal web server alla recezione della richiesta
- Attivo: contiene script o programmi che verranno eseguiti nel browser (ovvero lato client)
HTTP Quindi, HTTP si basa sul modello Client/Server. Il protocollo definisce in che modo i client devono richiedere le pagine e come i server devono trasferirle ai client.
Lato Client
- Il browser determina dall’URL host e nome del file
- Esegue la connessione TCP alla porta 80 (standard)
- Invia una richiesta per il file
- Riceve il file
- Chiude la connessione
- Visualizza il file
Lato Server
- Accetta la connessione TCP dal client
- Riceve il nome del file richiesto
- Recupera il file dal disco
- Invia il file al client
- Chiude la connessione
Connessioni HTTP
Connessioni non persistenti Un solo oggetto viene trasmesso su una connessione TCP. Ciascuna coppia richiesta/risposta viene inviata su una inviata su una connessione TCP separata. Prima di inviare una richiesta al server è necessario stabilire una connessione.
Connessioni persistenti Modalità di default. Più oggetti possono essere trasmessi su una singola connessione TCP tra client e server. La connessione viene chiusa quando rimane inattiva per un lasso di tempo (timeout) configurabile.
Schema del tempo di risposta
Per calcolare il tempo di risposta in queste connessione definiamo il concetto di RTT.
RTT (Round Trip Time)
E’ il tempo che impiega un pacchetto per raggiungere il server, partendo dal client, e tornare indietro.
Inoltre, include i ritardi di propagazione, accodamento e di elaborazione del pacchetto.
Il tempo di risposta è dato da:
- Un RTT per inizializzare la connessione TCP
- Un RTT per la richiesta HTTP e i primi byte della risposta
- Tempo di trasmissione del file
- Quindi in totale:
Se utilizziamo connessioni persistenti abbiamo un RTT per aprire la pagina RTT per ogni richiesta. E’ molto più veloce, ma le connessioni sono sequenziali.
Formato dei messaggi in una richiesta HTTP
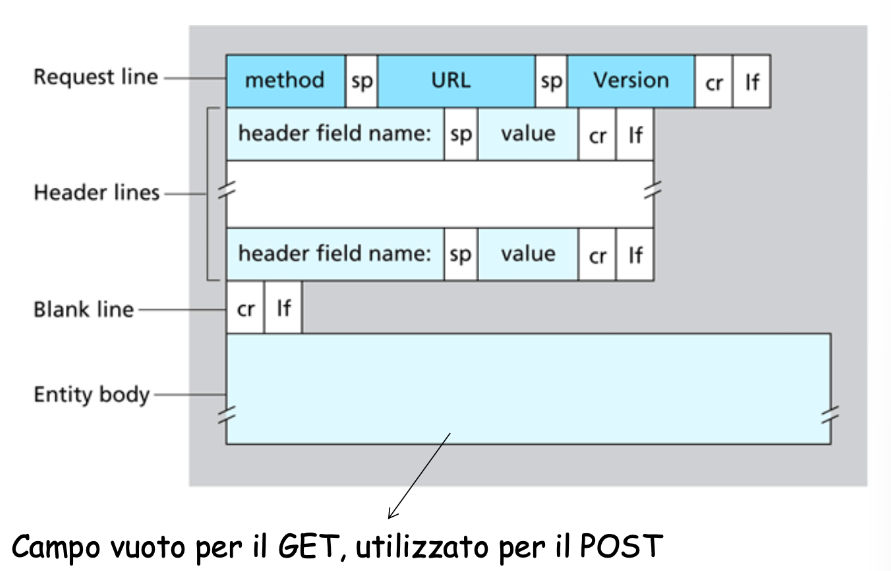
Esempio Vediamo un esempio:
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/4.0
Accept-language:fr- La prima riga è riga di richiesta dove vengono inseriti i comandi GET-POST-HEAD
- Le successive sono righe di intestazione
- A fine messaggio troviamo *carriage return e un life feed
Upload dell’input di un form
Metodo POST: la pagina web spesso include un form per l’input. La pagina web spesso include un form per l’input dell’utente. L’input arriva al server nel corpo dell’entità.
Metodo GET: come alternativa al metodo POST, possiamo usare il GET inserendo i dati del form nell’URL richiesto

Formato dei messaggi di risposta
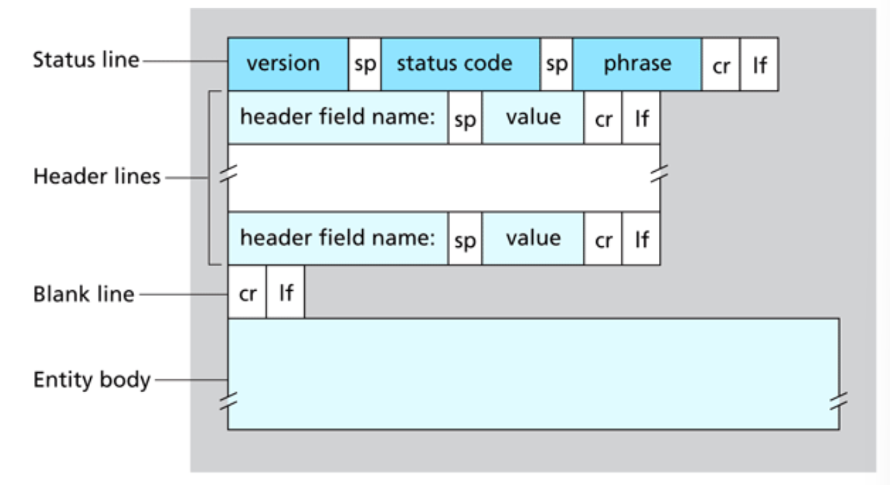
In questo caso i nomi diventano:
- La prima riga prende il nome di riga di stato
- Troviamo sempre le righe di intestazione
- Possiamo trovare altri dati come ad esempio gli oggetti richiesti
Esempio
HTTP/1.1 200 OK
Connection close
Date: Thu, 06 Aug 1998 12:00:15 GMT
Server: Apache/1.3.0 (Unix)
Last-Modified: Mon, 22 Jun 1998 ...
Content-Lenght: 6821
Content-Type: text/html
---
(altri dati)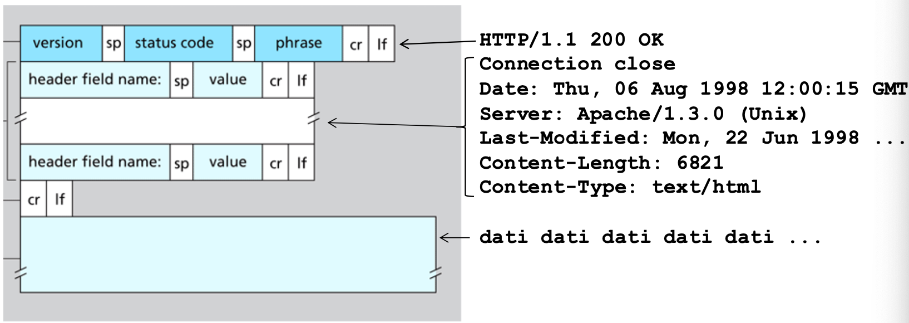
Codici di stato
- 200 okay: richiesta accettata
- 301 moved permanently: L’oggetto richiesto è stato trasferito; la nuova posizione è specificata nell’intestazione Location: della risposta
- 400 Bad Request: Il messaggio di richiesta non è stato compreso dal server
- 404 Not Found: Il documento richiesto non si trova su questo server
- 505 HTTP Version Not Supported: Il server non ha la versione di protocollo HTTP
In generale la prima cifra del numero indica che tipo è il codice:
- 1xx: messaggi di Informazione
- 2xx: successo
- 3xx: reindirizzamento
- 4xx: client Error
- 5xx: server Error
Cookie

HTTP è un protocollo senza stato (stateless), se un client fa più richieste a uno stesso server, non mantiene informazioni sulle richieste fatte. I protocolli che mantengono lo stato sono molto complessi dato che si deve memorizzare tutto ciò che fa il client. In caso di errore, le viste sullo stato di client e server potrebbero essere contrastanti.
In molti casi il server ha bisogno di ricordarsi degli utenti (es. per offrire contenuti personalizzati in base alle preferenze di ogni utente). Per questo, sono stati introdotti i cookie con lo scopo di creare una sessione di richieste e risposta HTTP “con stato”.
Sessione Ha un tempo di vita relativamente corto e sia il client che il server possono interromperla.
Interazione utente-server con i cookie
Servono quattro componenti:
- Una riga di intestazione che viene inserita nei messaggi di risposta HTTP
- Una riga di intestazione che viene inserita nei messaggi di richiesta HTTP
- Un file cookie mantenuto sul sistema terminale dell’utente e gestito dal browser dell’utente
- Un data base sul server
Il server mantiene tutte le informazioni riguardanti il client su un file e gli assegna un identificatore di sessione (SID), composto da una stringa complessa di numeri.
Ad ogni richiesta il browser consulta il file del cookie, estrae quello che necessario per quel sito web e lo inserisce in ogni richiesta HTTP. Infine, il server può riconoscerlo e mostrare dei contenuti personalizzati.
Durata di un cookie
Quando il server chiude una sessione, invia al client un’intestazione Set-Cookie. Dopodiché, il server cancella i cookie mettendo nel messaggio Max-Age = 0.
Caching
Serve per migliorare le prestazioni dell’applicazione web, può essere gestito in diversi modi:
- L’utente può impostarla in modo tale che dopo alcuni giorni i contenuti vengano cancellati
- La pagina può essere mantenuta in base alla sua ultima modifica
- Si possono utilizzare informazioni nei campi intestazione dei messaggi per gestire la cache
Server proxy
E’ un intermediario tra i vari client e sever e mantiene le copie delle pagine visitate in cache. Quindi, se tre client richiedono una pagina, il proxy riceve le richieste e ne invia una sola al server.
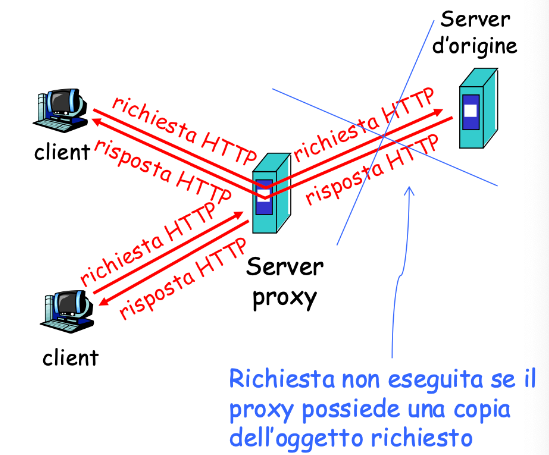
La cache serve a ridurre i tempi di risposta per i client, ridurre il traffico sul collegamento ad Internet e permettere ad ISP meno efficienti di fornire i dati in maniera veloce.
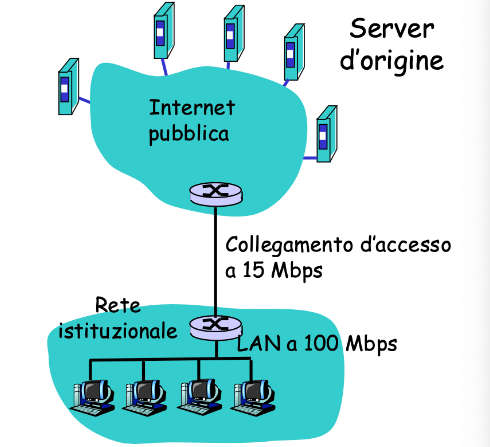
Esempio con assenza di cache
- Dimensione media degli oggetti
- I browser della rete effettuano
- Per recuperare un file sulla internet ci vogliono
- Il tempo totale di risposta è quindi
Facciamo una stima del ritardo calcolando
- Utilizzo della LAN:
- Utilizzo del collegamento d’accesso
- L’intensità tende a e il ritardo diventa importante
- Come ritardo totale otteniamo
Come soluzione potremmo aumentare l’ampiezza di banda del collegamento a e raggiungere quindi un utilizzo sul collegamento del e avere un ritardo notevolmente ridotto. Ma fare questo non è sempre possibile dato che è molto costoso aggiornare l’intero collegamento.
Oppure possiamo inserire una cache nella rete:
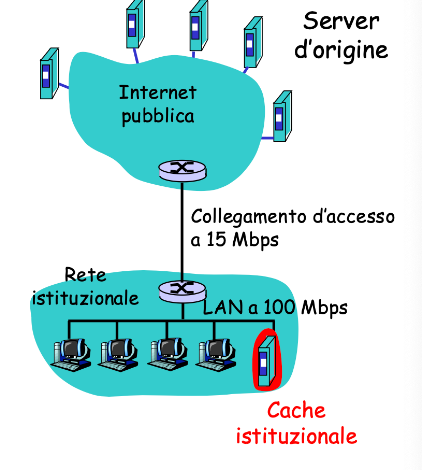
Supponiamo di avere una probabilità di successo pari a , ovvero una hit nella cache. Otteniamo quindi:
- Il delle richieste sarà soddisfatto immediatamente, nell’ordine dei
- Il delle richieste sarà soddisfatto dal server d’origine
- L’utilizzo del collegamento si è ridotto dal al portandoci ad avere dei ritardi trascurabili di circa
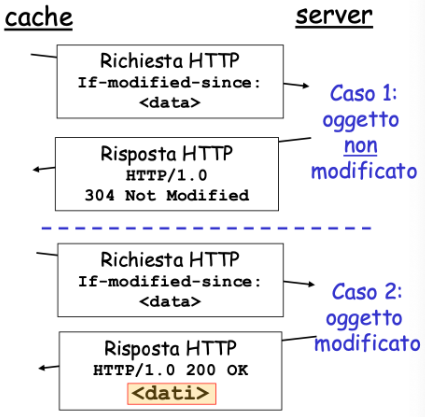
Inserimento di un oggetto in Cache
Il client invia un messaggio di richiesta HTTP alla cache:
GET /page/figure.gif
Host: www.sito.comLa cache non ha l’oggetto e invia una richiesta HTTP al server, il quale risponde con l’oggetto richiesto. La cache memorizza la pagina per richieste future e spedisce la risposta al client.
Se invece la cache ha l’oggetto in memoria allora può inviarlo al client, ma prima deve validarlo per verificare che non sia stato modificato dal server. Per fare questo tipo di verifica, viene utilizzato il GET condizionale che utilizza degli if.
In tal modo, se la cache ha una copia aggiornata allora l’oggetto non verrà rinviato.
DNS
Identificazione degli host
Gli host internet hanno nomi (hostname) facili da ricordare, ma forniscono poca informazione sulla collocazione degli host all’interno di internet. Per questo, vengono utilizzati gli indirizzi IP.
Indirizzi IP
Sono composti da 32 bit e vengono utilizzati per indirizzare i datagrammi.
Possiamo rappresentarli come stringhe dove ogni byte (4 byte = 32 bit) rappresenta un numero decimale compreso tra 0 e 255 ed ognuno di questi 4 numeri è separato da un ., ad esempio: 121.34.230.94
Questo formato serve anche per creare una gerarchia negli indirizzi. Infatti, tramite l’indirizzo IP possiamo ricavare la rete di appartenenza e l’indirizzo del nodo.
Come facciamo, dunque, a ricavare un hostname utilizzabile da un indirizzo IP? Utilizziamo il DNS (Domain Name System).
DNS
Questo protocollo, prende in input il nome di una macchina e ci dice qual è il suo indirizzo IP. Con l’indirizzo IP, possiamo rappresentare indirizzi in totale e tutte queste coppie devono essere accessibili.
Per la memorizzazione degli indirizzi, si utilizza un database distribuito su una gerarchia di server DNS. Invece, per quanto riguarda l’accessibilità, si fa uso di un protocollo a livello applicazione che consente agli host di interrogare i database dei server ed eseguire la traduzione
Il DNS deve mantenere le informazioni e recuperarle velocemente, e per questo, organizza le informazioni in modo gerarchico. Viene utilizzato da tutte le applicazioni per tradurre gli hostname e utilizza per il trasporto l’UDP, utilizzando la porta 53.
Viene utilizzato l’UDP perché si hanno meno overhead, cioè pacchetti aggiuntivi utilizzati non per trasmettere dati, ma per gestire le connessioni. Infatti, i messaggi DNS sono molto corti e una connessione TCP richiede più tempo.
In generale (Esempio con HTTP):
- Un client HTTP richiede un URL ad esempio
www.google.com - Il browser prende il nome dell’host dall’URL e lo passa al lato client DNS
- Il client DNS invia una query ad un server DNS
- Il client DNS riceve una risposta che contiene l’indirizzo IP corrispondente all’hostname
- Adesso il browser può dare inizio alla connessione TCP verso il server HTTP localizzato a quell’indirizzo IP
Warning
Quindi, il DNS non è un’applicazione vera e propria utilizza direttamente dall’utente
Aliasing
Aliasing
Il DNS permette di associare uno o più nomi semplici da ricordare a un nome complesso.
Per esempio, server1.euw.azienda.com potrebbe avere dei sinonimi più semplici come azienda.com.
Quindi il primo, più “complesso” è l’hostname canonico, mentre il secondo si chiama alias. Il funzionamento è uguale a quello per la traduzione tra indirizzo IP e nome host. Quindi, se un client chiede un alias, riceverà nome canonico e indirizzo IP.
Siti con molto traffico vengono replicati su più server e ciascuno di questi gira su un sistema terminale diverso e presenta un indirizzo IP diverso.
Gerarchia Server DNS
Inizialmente il DNS doveva tradurre pochi indirizzi e in poche reti e quindi era sufficiente salvarli in un file di testo che veniva aggiornato ogni notte. Ora, però, non può essere centralizzato perché è un’applicazione che gira su un gran numero di server sparsi per il mondo.
Se fosse centralizzato, si avrebbero una serie di conseguenze:
- Il server crasherebbe e Internet diventerebbe praticamente inutilizzabile
- Si avrebbero troppe richieste da gestire per un singolo server
- Un solo server non potrebbe mai essere vicino ad ogni client del mondo e quindi rallenterebbe le persone più lontane
- Il server va aggiornato spesso per aggiungere nuovi nomi e con uno singolo sarebbe molto difficile anche mantenerlo online
- Non sarebbe scalabile
Quindi, si utilizza una gerarchia di server che segue le seguenti “regole”:
- Nessun server deve mantenere tutti le coppie hostname - indirizzo IP
- Mapping (traduzione) distribuito su svariati server
Ma come memorizziamo le coppie in modo da renderle velocemente accessibili da tutti i client?
Innanzitutto, raggruppiamo i nomi in base al dominio. Per esempio:
- `www.uniroma1.it
www.google.comwww.unipi.itwww.cnr.itwww.umass.edu
Per fare una ricerca in tempi rapidi, si raggruppano le coppie (IP e nomehost) in base al dominio.
Ci sono tre classi di server DNS organizzati in una gerarchia:
- Root
- Top-level domain
- Authoritative
Ci sono poi i server DNS locali con cui interagiscono direttamente le applicazioni.
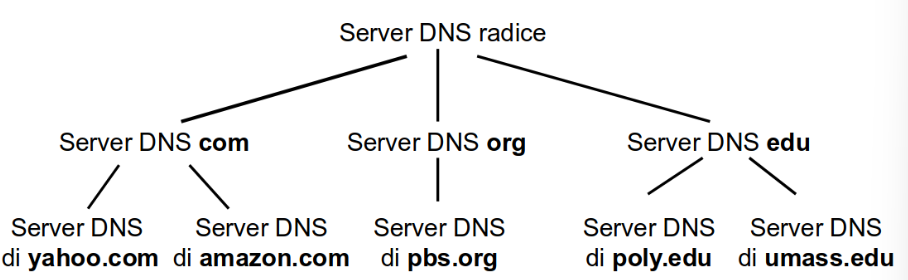
Se ad esempio richiediamo la pagina www.amazon.com:
- La richiesta arriva al server root il quale gli dirà dove trovare il server
.com - Il server TLD gli dirà dove trovare il server
amazon.com - Il server di amazon gli dirà dove trovare
www.amazon.com
Server TLD
Sono server che si occupano dei domini com, org, net, edu.... Per esempio, in Italia abbiamo il Registro.it che ha sede a Pisa nel CNR e gestisce il dominio .it.
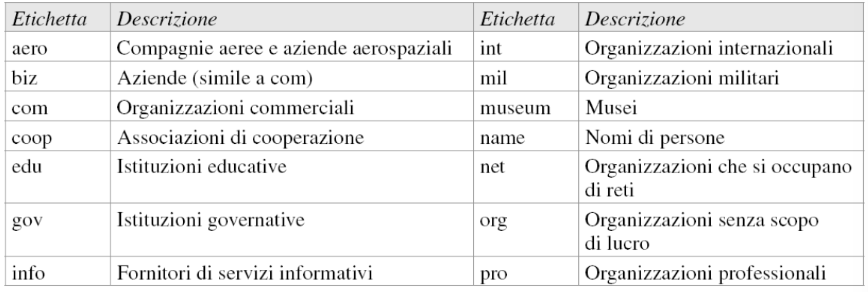
Etichette di domini
Server di competenza (o authoritative server) Ogni organizzazione avrà il suo authoritative server in modo da rendere pubblici i suoi hostname, questi sono gestiti direttamente dall’organizzazione e di solito ce ne sono due, uno primario e uno secondario.
Server DNS locale (o default name server) Non appartiene direttamente alla gerarchia dei server dato che è interno agli ISP o organizzazioni. Quando un host effettua una richiesta DNS, la query viene inviata al suo server DNS locale che agisce come un proxy inoltrando la query in una gerarchia di server.
Gestione delle query all’interno della gerarchia
Query iterativa
L’host invia la richiesta al server DNS locale, che a sua volta la inoltra a un server root. Questo indica dove trovare il server TLD, il quale fornisce l’indirizzo del server di competenza (authoritative). Quest’ultimo, infine, individua la pagina richiesta e la restituisce all’host.
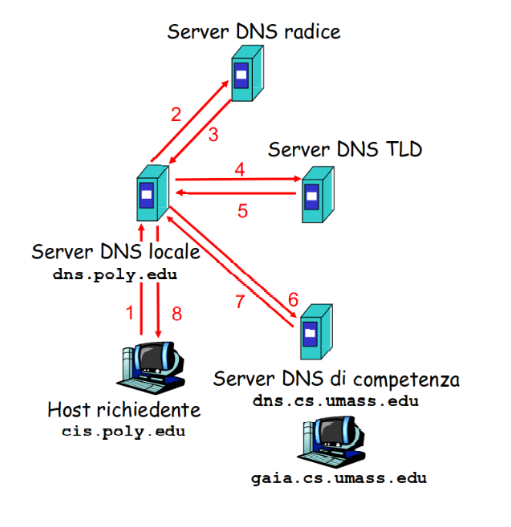
Notiamo che per fare la mappatura di un hostname sono stati inviati 8 messaggi.
Query ricorsiva
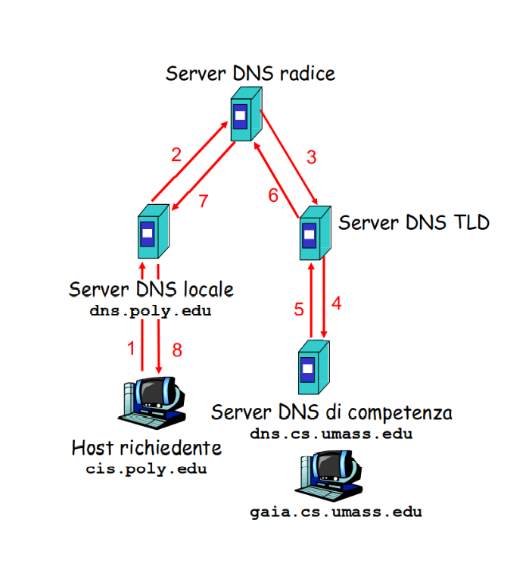
L’host (cis.poly.edu), vuole risolvere un nome di dominio, invia la richiesta al proprio server locale, (dns.poly.edu).
Se questo non ha già la risposta, si occupa di trovarla per conto dell’host, avviando una risoluzione ricorsiva.
Il server locale interroga prima un server root che gli indica quale server TLD può gestire la richiesta. A sua volta, il server TLD fornisce l’indirizzo del server di competenza, responsabile del dominio richiesto.
Una volta contattato, il server di competenza restituisce l’indirizzo IP corrispondente. Il server locale riceve questa informazione e la invia all’host, che ora può accedere alla risorsa desiderata.
In questo processo, l’host si limita a fare una sola richiesta, mentre è il server locale a gestire l’intera ricerca, contattando i vari server e raccogliendo la risposta.
Record e messaggi
Il mapping è mantenuto all’interno di server sottoforma di resource record (RR), ognuno di questi mantiene un mapping tra hostname, indirizzo IP, alias, nome canonico e altro.
I server quindi si scambiano questi record attraverso i messaggi DNS, un messaggio può contenere più RR.
Record DNS Questi sono memorizzati all’interno del database e vengono trasportati dai messaggi, hanno questa struttura:
(Name, Value, Type, TTL)dove:- TTL è il tempo residuo di vita
- Type ha vari valori e fa a seconda di questo fa cambiare il significato di
nameevalue
Se Type vale A:
- Allora il record contiene una mappatura Hostname → IP address e quindi troveremo sul campo
namel’hostname e sul campovaluel’indirizzo IP
Se Type vale CNAME:
- Si tratta di una traduzione fra alias e nome canonico, avremo su
namel’alias e suvalueil nome canonico
Se Type vale NS:
- Il record mappa un dominio in un name server quindi avremo su
nameil dominio come ad esempiouniroma1.ite suvalueil nome dell’host del server authoritative di quel dominio come ad esempiodi.uniroma1.it
Se Type vale MX:
- Si sta mappando Alias → nome canonico del mail server, quindi avremo che
valueè il nome canonico del server di posta associato aname
In generale:

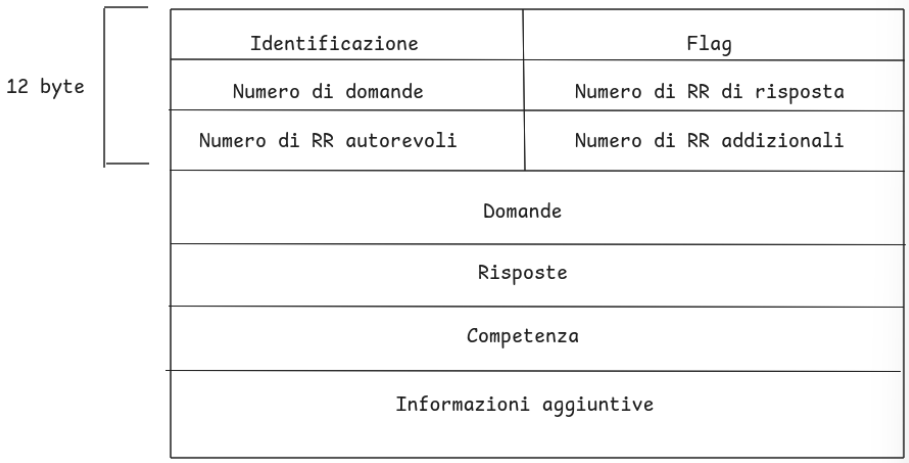
Messaggi DNS Le query e le risposte hanno lo stesso formato nel protocollo DNS.
Abbiamo un’intestazione da 12 byte che comprende:
- Identificazione: numero di 16 bit per la domanda e la risposta usa lo stesso numero
- Flag che indicano:
- Domanda o Risposta
- Richiesta di ricorsione
- Ricorsione disponibile
- Risposta di competenza (se il server non è competente per quel nome)
- Numero di:
- Domande
- RR di risposta
- RR autorevoli
- RR addizionali
Fuori l’intestazione troviamo i blocchi per le informazioni che ci erano state date nella sezione “numero di”.
- Domande: Campi per il nome richiesto e il tipo di domanda (A, MX, NS…)
- Risposte: RR per la risposta, se abbiamo replicati ci saranno più RR
- Competenza: Record per i server di competenza
- Informazioni aggiuntive: Informazioni extra che possono essere utili come ad esempio in una risposta MX dove il campo risposta contiene il record MX con il nome canonico del server di posta mentre in questo campo aggiuntivo c’è un record di tipo A con l’indirizzo IP relativo all’hostname canonico del server di posta.
Protocollo FTP
Permette di trasferire file da una macchina remota o di inviarvi file. Il comando per accedervi è
ftp NomeHost
Per il trasferimento si usa
ftp > get dsvdsvcs
Quando l’utente fornisce il nome dell’host remoto, il processo client FTP stabilisce una connessione TCP
- Connessione controllo: persistente e dura tutto il tempo in cui noi siamo connessi
- Connessione dati: si occupa del trasferimento di file
Caratteristiche di FTP
FTP ha una connessione di controllo out of band Il server FTP mantiene lo stato.
Connessione dati
Quando il server riceve un comando per trasferire un file, apre una connessione dati TCP sulla porta 20 con il client.
Dopo il trasferimento di un file, il server chiude la connessione
Posta elettronica
Nelle altre applicazioni, quando inviamo un messaggio, attendiamo una risposta. Quando mandiamo una email, per esempio, non viene tornato nessun messaggio. Non abbiamo la certezza che il destinatario abbia letto subito il messaggio.
La caratteristica è che è un’app asincrona. Manda un messaggio, ma non sa quando il destinatario leggerà il messaggio. L’email parte da un utente mittente a un utente destinatario. Al livello di struttura abbiamo il user agent usato per scrivere e inviare un messaggio o leggerlo. Il message transfer agent è usato per trasferire il messaggio attraverso la rete Il message access agent: viene usato per leggere la mail in arrivo
User agent
E’ il programma che utilizziamo per comporre e leggere le email. I messaggi in uscita e in arrivo sono memorizzati nel server. Il messaggio viene passato al mail transfer agent.
Message transfer agent vedi slide
SMTP Usa TCP per trasferire on modo affidabile i messaggi di posta elettronica dal cliente al server, utilizzando la porta 25.
Ha tre fasi nel momento in cui viene inviata una mail:
- handshaking: i server si “mettono d’accordo”
- trasferimento di messaggi
- chiusura
L’interazione comando/risposta
- comandi: testo ASCII
- risposta: codice di stato ed espressione
Scambio di messaggi
Il client SMTP fa stabilire una connessione sulla porta 25 verso il server SMTP Se il server è inattivo i client riprova più tardi Se è attivo, viene stabilita una connessione. vedi slide
Confronto HTTP e FTP
vengono utilizzati per trasferire file da un host all’altro. HTTP: gli utenti scaricano i file e inizializzano una connessione TCP FTP: spedisce il file e inizializza la connessione TCP
HTTP: ciascun oggetto è incapsulato nel suo messaggio di risposta FTP: più oggetti vengono trasmessi in un unico messaggio.
Protocollo MIME
Utilizzando quando si devono inviare messaggi in formato non ASCII vedi slide
Protocollo POP 3
Permette al client ricevente la posta di aprire una connessione TCP verso il server di posta sulla porta 110. Quando la connessione è stabilita, si procede in 3 fasi:
- Autorizzazione
- Transazione
- Aggiornamento
Livello di trasporto
Due tipi di servizi:
- Affidabile
- Non affidabile: non so quanto di quello che invio arrivi a destinazione
A livello di trasporto ci sono processi che si basano sui servizi del livello di rete e li potenzia. A livello di rete dsfdsdsf
Indirizzamento
La maggior parte dei sistemi operativi è multiutente e multiprocesso
- Diversi processi client attivi (host locale)
- Diversi processi server attivi (host remoto)
Per stabilire una comunicazione tra i due processi è necessario un metodo per individuare:
- host locale
- host remoto
- processo locale
- processo remoto
L’indirizzamento è dato dai numeri di porta
L’indirizzo IP è l’indirizzamento a livello di rete, la porta è l’indirizzamento al livello di trasporto.
Socket API
interfaccia tra il livello di trasporto e livello applicazione Appare come un file o un terminale, ma è una struttura dati creata e utilizzata dal programma applicativo.
Il socket address contiene due informazioni, numero di porta + indirizzo IP.
Numeri di porta
- 16 bit address
- numero di porta well known
Individuare i socket address
Il client ha bisogno di un socket address locale e uno remoto per comunicare
Socket address locale: fornito dal sistema operativo
- Conosce l’indirizzo IP del computer su cui il client è in esecuzione
- Il numero di porta è assegnato temporaneamente dal sistema operativo (numero di porta effimero o temporaneo – non utilizzato da altri processi)
Socket address remoto
- Numero di porta noto in base all’applicazione (http porta 80)
- Indirizzo IP fornito dal DNS (Domani Name System)
- Oppure porta e indirizzo noti al programmatore quando si vuole verificare il corretto funzionamento di un’applicazione (esempi sul libro di testo)
Anche il server ha bisogno di un socket address locale e uno remoto Socket address locale: fornito dal sistema operativo
- Conosce l’indirizzo IP del computer su cui il server è in esecuzione
- Il numero di porta è noto al server perché assegnato dal progettista (numero well known o scelto)
Socket address remoto
- è il socket address locale del client che si connette
- Poiché numerosi client possono connettersi, il server non può conoscere a priori tutti i socket address, ma li trova all’interno del pacchetto di richiesta
N.B. il socket address locale di un server non cambia (è fissato e rimane invariato), mentre il socket address remoto varia ad ogni interazione con client diversi (anche con stesso client su connessioni diverse)
Servizi dei protocollo di trasporto Internet
TCP
Orientato alla connessione., è richiesto un setup fra processi client e server L’utente deve stabilire una connessione e quindi rilasciarla
E’ affidabile: fra processi di invio e di ricezione C’è il controllo della congestione, si allarga a più nodi della rete. E’ un problema di ciò che c’è in mezzo a mittente e destinatario. Non offre temporizzazione, garanzie su unm’’ap i ezza di banda minima, sicurezza (alcune possono essere implementate, Es. SSL)
UDP
E’ un protocollo non affidabile e quindi senza connessione. Non c’è alcun setup tra i processi client e server Due messaggi mandati dalla stessa connessione possono arrivare con latenze importanti. non offre: setup della connessione, affidabilità, controllo di flusso, controllo della congestione, temporizzazione né ampiezza di banda minima e sicurezza E’ utilizzata perché è veloce
UDP nel dettaglio
E’ un protocollo di trasporto inaffidabile e privo di connessione Gli unici servizi che offre:
- Comunicazione tra processi utilizzando i socket
- Multiplexing/demultiplexing dei pacchetti
- Incapsulamento e decapsulamento
- Datagrammi indipendenti, non numerati
Non fornisce alcun controllo di flusso, errori (eccetto checksum), congestione
Processo client e processo server Il processo client passa le richieste al processo client di trasporto che le invierà all’applicazione di destinazione.
Servizio senza connessione significa che: il mittente deve dividere i suoi messaggi in porzioni di dimensioni accettabili dal livello di trasporto a cui consegnarli uno per uno. Ogni pacchetto è indipendente dagli altri (la sequenza di arrivo può essere diversa da quella di spedizione) Non c’è coordinazione tra livello trasporto mittente e destinatario
Rappresentazioni con macchine a stati finiti
Il mittente riceve richieste dall’applicazione, le incapsula e le invia Il destinatario riceve dalla rete il pacchetto, lo decapsula e lo passa al livello applicazione
Datagrammi UDP
vedi slide 31
Struttura datagrammi
32 bit per l’intestazione All’interno dell’header abbiamo la lunghezza e il checksum che controlla la correttezza del pacchetto.
Checksum UDP
Rileva gli errori (bit alterati) nel datagramma trasmesso. vedi slide 33 e 34
DNS usa UDP
Quando vuole effettuare una query, DNS costruisce un messaggio di query e lo passa a UDP. L’entità UDP aggiunge i campi di intestazione al messaggio e trasferisce il segmento risultante al livello di rete, etc. L’applicazione DNS aspetta quindi una risposta Se non ne riceve tenta di inviarla a un altro server dei nome La semplicità della richiesta/risposta (molto breve) motiva l’utilizzo di UDP, che risulta più veloce
- Nessuna connessione stabilita
- Nessuno stato di connessione
- Intestazioni di pacchetto più corte
UDP è utilizzato anche perché consente un controllo più sottile a livello di applicazione su quali dati sono inviati e quando
Utilizzato spesso nelle applicazioni multimediali
- Tollera perdite di pacchetti (limitate)
- sensibile alla frequenza
TCP
Offre un trasporto orientato alla connessione, controllo del flusso, controllo degli errori e controllo della congestione
Stop and wait
Meccanismo orientato alla connessione + controllo di flusso + controllo degli errori
Il mittente e il destinatario usano una finestra scorrevole di dimensione 1 Il mittente invia un pacchetto alla volta e ne attende l’ack prima di spedire il successivo
Se il pacchetto è corretto arriva l’ack al mittente. Altrimenti viene scartato senza informare il mittente.
Abbiamo una sola locazione (una sola finestra di invio e una sola finestra di ricezione). La finestra di invio serve per memorizzare cosa è stato inviato e in caso inviare nuovamente il pacchetto se viene perso.
Il controllo degli errore viene controllato attraverso un numero sequenza + ack + controllo degli errori
Numeri di sequenza
vedi slide 4
Il destinatario si accorge se si mandano duplicati attraverso il numero di sequenza. I numeri di sequenza 0 e 1 sono sufficienti per il protocollo stop and wait Convenzione: il numero di riscontro (ack) indica il numero di sequenza del prossimo pacchetto atteso dal destinatario Se il destinatario ha ricevuto correttamente il pacchetto 0 invia un riscontro con valore 1 (che significa che il prossimo pacchetto atteso ha numero di sequenza 1)
Efficienza di stop and wait
Consideriamo il prodotto rate*ritardo (misura del numero di bit che il mittente può inviare prima di ricevere un ack, volume della pipe in bit)
- Se rate elevato e ritardo consistente
- è stop and wait inefficiente
Protocolli con pipeline
Invio tanti pacchetti e aspetto che nel frattempo mi torni l’ack Nel frattempo che aspetto gli ack, libero spazio e ne mando altri
Abbiamo un intervallo di numeri di sequenza più ampio.
Go back N
Abbiamo una finestra di invio di più locazioni e una finestra di invio con una sola locazione
Rispetto allo stop and wait i numeri di sequenza sono dove m è la dimensione del campo “numero di sequenza” in bit
L’ack indica in numero di sequenza del prossimo pacchetto atteso
Ack cumulativo: tutti i pacchetti fino al numero di sequenza indicato nell’ack sono stati ricevuti correttamente
Quando mi arriva l’ack posso scorrere di più posizioni i pacchetti da inviare
Finestra di ricezione
La finestra di ricezione ha dimensione 1 Il destinatario è sempre in attesa di uno specifico pacchetto, qualsiasi pacchetto arrivato fuori sequenza (appartenente alle due regioni esterne alla finestra) viene scartato
Timer di rispedizione Il timer è associato al pacchetto più “vecchio” Allo scadere del timer vengono rispediti tutti i pacchetti in attesa di riscontro. Questo perché il destinatario non può bufferizzare perché ha una sola locazione
TCP
- Protocollo con pipeline
- Bidirezionale (ack in piggybacking)
- Orientato al flusso di dati (stream-oriented)
- Orientato alla connessione
- Affidabile (controllo degli errori)
- Controllo del flusso
- Controllo della congestione
Il TCP riceve il pacchetto dal livello applicazione.
Struttura dei segmenti
Composto da una porta sorgente una porta destinazione.
Numero di sequenza Numero che identifica il pacchetto. Il TCP numera i pacchetti in base al numero di byte nella sequenza.
Numeri di riscontro Si riferisce al byte ricevuti, in base all’ack ricevuto.
Byte flag
Assumono significato quando valgono 1.
Tre flag (ack, syn e fin) che servono per stabilire la connessione.
Se ack = 1, il segmento è un’ack
sym = 1, segmento di sincronizzazione
fin = 1, segmento di chiusura di connessione
Stabilire una connessione
E’ un aspetto virtuale, mittente e destinatario si scambiano pacchetti di controllo.
3 fasi
- apertura connessione
- scambio dati
- chiusura
Trasferimento dati: urgent
Se ci sono dati urgenti, vengono messi all’inizio del pacchetto. Quando il destinatario riceve i messaggi urgenti, vengono elaborati subito dall’applicazione.
Chiusura della connessione
Il client o il server chiude la connessione. C’è uno scambio come quello di apertura.
Controllo degli errori
- Checksum: Se un segmento arriva corrotto viene scartato dal destinatari
- Riscontri + timer di ritrasmissione
- Ritrasmissione
- Ritrasmissione del segmento all’inizio della coda di spedizione
Controllo della congestione
Ci si accorge della congestione quando i pacchetti vengono smarriti oppure quando ci sono lunghi ritardi
La congestione si crea nei router
Problematiche nella gestione della congestione
Finestra di congestione
Per controllare la congestione si usa la variabile CWND (congestion window) che insieme a RWND definisce la dimensione della finestra di invio
- CWND: relativa alla congestione della rete
- RWND: relativa alla congestione del ricevente
Rilevare la congestione
Per controllare la congestione si usa la variabile CWND (congestion window) che insieme a RWND definisce la dimensione della finestra di invio
- CWND: relativa alla congestione della rete
- RWND: relativa alla congestione del ricevente
Controllo della congestion
Idea di base: incrementare il rate di trasmissione se non c’è congestione (ack), diminuire se c’è congestione (segmenti persi) L’algoritmo di controllo della congestione si basa su tre componenti
- Slow start
- Congestion avoidance
- Fast recovery
Slow start
Cwnd inizializzata a 1 MSS
- Poiché la banda disponibile può essere molto maggiore, slow start incrementa di 1MSS la cwnd per ogni segmento riscontrato
LA cwnd cresce esponenzialmente fino a raggiungere una soglia

Congestion avoidance
Cresce linearmente Ogni volta che viene riscontrata l’intera finestra di segmenti, si incrementa di 1 la cwnd
Aumento fin quando ci sono timeout o ack duplicati
Generalizzando possiamo dire che la cwnd aumenta fino alla rivelazione della congestione
Come vengono definiti al livello del TCP?
TCP Taho
Si comincia con la slow start mandando un pacchetto, incremento di uno fin quando non ricevo un ack e aumento di uno.
Quando sto in congestion avoidance, incremento di uno e torno indietro se ho timeout o ack duplicati
Affinamento
Oss: C’è una differenza tra l’evento del timeout e dei tre ack duplicati
Ack duplicati vuol dire che i segmenti arrivano non in ordine Il timeout significa che i pacchetti non stanno arrivando e indica una congestione più grave
TCP Reno
Quando il timeout significa che ho una congestione più importante e quindi si riparte da 1
3 ack duplicati: congestione lieve
- applica fast recovery a partire da ssthreshold + 3
Come si imposta il timeout?
Deve dipendere dal RTT. Ma il RTT non dipende solo dalla distanza che attraversa, ma anche dalla congestione. Dobbiamo considerare il tempo di accodamento nel router
Si deve stimare il RTT e far variare il timeout in base al RTT Per ogni segmento che spedisco posso stimare il RTT
Come si stima? SampleRTT: tempo misurato dalla trasmissione del segmento fino alla ricezione di ACK
- ignora le ritrasmissioni
- Un solo SampleRTT per più segmenti trasmessi insieme Varia a causa di una congestione nei router e carica nei sistemi terminali, quindi serve una stima “più livellata” di RTT
- Media mobile esponenziale ponderata
- L’influenza delle misure passate decresce esponenzialmente
- peso (tipicamente )
Stima di quanto SampleRTT si discosta da EstimatedRTT
- Tipicamente
Livello di Rete
Il livello di rete nella pila dei protocolli è quello che si occupa di instradare i datagrammi dal mittente al destinatario. A differenza del livello di trasporto non stiamo più facendo comunicare processi, ma due host.
A livello di rete prende i segmenti del trasporto, li incapsula trasformandoli in datagrammi e li trasmette al router più vicino. Il datagramma viene, quindi, instradato tra i vari router fino a raggiungere l’host destinatario, dove viene decapsulato e inviato al livello successivo.
Funzioni del livello di rete
Routing Determina il percorso da seguire dall’origine fino alla destinazione. Più localmente, un router decide quale sarà il prossimo router su cui instradare il datagramma.
Forwarding Si occupa del trasferimento vero e proprio dei pacchetti sul percorso scelto dal routing.
Tramite gli algoritmi di routing vengono create delle tabelle di routing che verranno poi usate per il forwarding. Le tabelle associano ad ogni intestazione un collegamento d’uscita.
Switch e Router
Sono entrambi dei packet switch (commutatore di pacchetto) ovvero dei dispositivi che si occupano di trasferire dati da un’interfaccia di ingresso ad una di uscita in base ai valori presenti nei datagrammi.
- Link - layer switch (commutatore a livello di collegamento): stabilisce il percorso in base al campo presente nell’intestazione a livello di collegamento (livello 2). E’ usato per collegare singoli computer all’interno di una LAN
- Router: stabilisce il percorso in base al campo presente nell’intestazione a livello di rete (livello 3). Riceve un insieme di informazioni (pacchetto) e in base alle tabelle di routing decide quale sarà il prossimo router su cui instradarlo
Circuit switching e Packet switching
Reti a circuito virtuale In questo tipo di rete viene quindi stabilita una connessione virtuale e durante tutta la connessione i pacchetti seguiranno il percorso prestabilito inizialmente.
I pacchetti in un circuito virtuale hanno un’etichetta di circuito VC nella loro intestazione. In base a questo, il router sceglie il percorso su cui instradare il pacchetto. Il VC può essere diverso da router a router anche se si riferisce allo stesso percorso. Per questo, viene cambiato il VC durante il passaggio all’interno di un router.
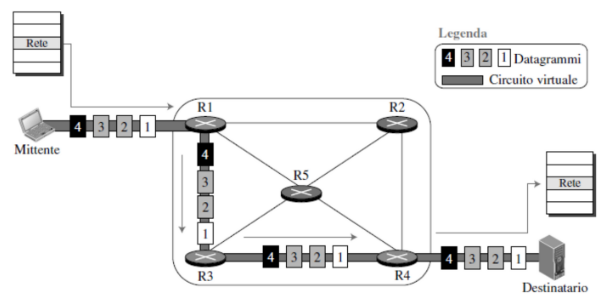
Come si implementa? Innanzitutto, serviranno:
- Un percorso tra due host
- Numeri di VC per ogni collegamento
- Righe nella tabella di intorno in ciascun router
- Il numero di VC rappresenta un etichetta di flusso e cambia su tutti i collegamenti del percorso
Esempio
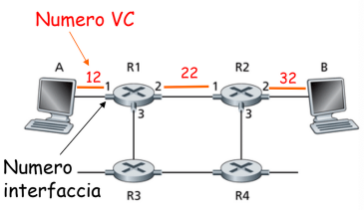
Possibile tabella di R1

- Entra nell’interfaccia 1 un pacchetto con VC 12
- Viene instradato sull’interfaccia 2 e gli viene cambiato il VC in 22
- R2 probabilmente avrà una regola secondo cui i pacchetti con VC 22 dall’interfaccia 1 vengono instradati sull’interfaccia 2 con VC 22
Per ogni connessione stabilita i router mantengono una linea nella tabella, quando una connessione viene rilasciata non ne hanno più bisogno e quindi la cancellano.
Reti a datagramma Internet è un datagramma (packet switched), quindi i router non conservano informazioni sui circuiti virtuali dato che non esistono vere e proprie connessioni a livello di rete. I pacchetti vengono semplicemente inoltrati in altri router in base al loro indirizzo di destinazione.
Questo significa che i pacchetti non seguiranno più lo stesso percorso. Infatti, potrebbero prendere ciascuno un percorso diverso per arrivare a destinazione.
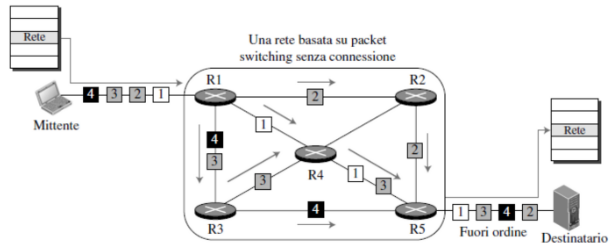
In questo caso la tabella di inoltro dei router sarebbe troppo grande se coprisse tutte le possibilità. Per scegliere il percorso, viene utilizzato il prefisso degli indirizzi.

- Se riceve
11001000 00010111 00010110 10100001verrà instradato sull’interfaccia 0 - Se riceve
11001000 00010111 00011000 10101010verrà instradato sull’interfaccia 1
Nel secondo caso scegliamo l’interfaccia 1 anche se il prefisso è uguale alla 2 perché abbiamo più cifre che combaciano sulla 1 (i 3 zeri che seguono i due 1).
Router
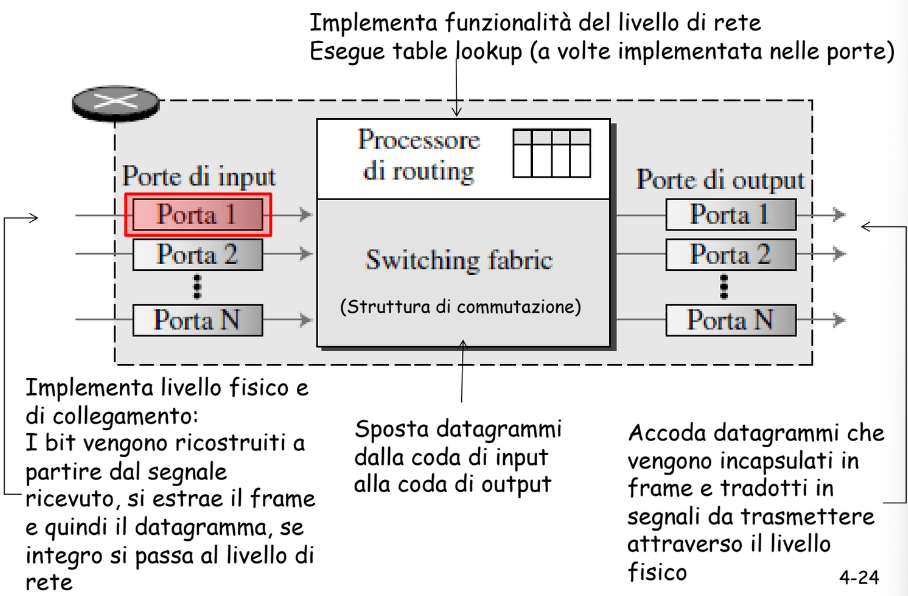
La commutazione può avvenire anche direttamente sulle porte, prende il come di commutazione decentralizzata. Questa è permessa da una copia della tabella d’inoltro nella porta d’ingresso.
Questo tipo di commutazione serve ad avere un’elaborazione allo stesso tasso della linea ed evitare i colli di bottiglia, cioè quando il tasso di arrivo è maggiore a quello di inoltro.
Una volta scelto il percorso, il pacchetto viene mandato alla switching fabric dove viene instradato sulla porta di output.
Sulle porte di output è presente quindi la funzionalità di accodamento che gestisce i colli di bottiglia e lo schedulatore di pacchetti che stabilisce in quale ordine spedire quelli accodati.
Routing
Sceglie il percorso (route) migliore per i pacchetti. Costruisce le tabelle e inserisce i dati al suo interno
Routing intra-dominio: RIP (routing information protocol)
Algoritmo di routing Possiamo identificare la rete con un grafo i cui nodi sono i router e gli archi sono i vari collegamenti tra router. Un path è una sequenza di nodi all’interno del grafo.
Su ogni arco c’è un costo. Il costo di un cammino è la somma di tutti i costi degli archi lungo il cammino
Qual è il cammino a costo minimo tra due nodi u e z? Si utilizza l’algoritmo d’instradamento con vettore delle distanze. Si basa sull’equazione di Bellman-Ford e il concetto di vettore di distanza.
Dove riguarda tutti i vicini di . è il costo del percorso a costo minimo dal nodo al nodo .
Vettore delle distanze Array in cui ogni nodi ha il suo array che contiene il costo verso gli altri nodi.
Ogni nodo della rete inizializza il proprio vettore mettendo i valori dei nodi con cui è collegato.
RIP
E’ un protocollo a vettore distanza E’ tipicamente incluso in UNIX BSD dal 1982 e la distanza è misurata in hop (max = 15 hop e 16 indica )
Livello di Collegamento
E’ il livello più basso dello stack protocollare. La comunicazione è hop-to-hop
i router e host vengono genericamente chiamati nodi o stazioni. Il protocollo di collegamento si occupa della trasmissione dei datagrammi lungo un collegamento.
I collegamenti possono essere:
- punto-punto: collega direttamente due dispositivi
- condiviso da più di due nodi
Un datagramma può essere gestito da diversi protocolli.
Servizi
Framing Incapsulamento e aggiunta dell’intestazione. Per identificare origine e destinazione vengono utilizzati gli indirizzi MAC.
Consegna affidabile Basata sull’ack come nel trasporto. E considerata necessaria nei collegamenti che presentano un basso numero di errori sui bit.
Controllo del flusso Evita che il nodo trasmittente saturi quello ricevente
Rilevazione degli errori Causati dalle interferenze, vedi slide
Il livello di collegamento è implementato nelle interfacce di rete.
Sottolivelli
Data link control (DLC) Occupa tutte le questioni comuni sia ai collegamenti puto-punto, che a quelli broadcast.
Media Access Control (MAC) Si occupa solo degli aspetti specifici dei canali broadcast
Metodi di persistenza
Definisce come si comporta il nodo quando deve trasmettere. Ascolta il canale, se è libero trasmette subito. Se il canale è occupato, può aspettare un tempo randomico per poi riascoltare il canale o rimanere in ascolto finché il canale si libera e in caso trasmette subito. Se c’è collisione va in back-off.
p persistente Se il canale è libero trasmette con probabilità e rimanda la trasmissione con probabilità
Se il canale è occupato usa la procedura di back-off (attesa di un tempo random e nuovo ascolto). Se c’è collisione fa back-off esponenziale.
Persistenza
Si riferisce all’approccio che si ha verso la trasmissione. Quanto si vuole trasmettere subito.
Protocolli MAC a rotazione
Protocolli MAC a suddivisione del canale Condividono il canale equamente ed efficientemente con carichi elevati ed è inefficiente con carichi elevati.
Protocolli MAC ad accesso casuale Efficienti anche con carichi non elevati: un singolo nodo può utilizzare interamente il canale. Carichi elevati: eccesso di collisioni.
Protocolli a rotazione Cercano di realizzare un compromesso tra i protocolli precedenti. Un nodo principale sonda “a turno” gli altri. In particolare:
- elimina le collisioni
- elimina gli slot vuoti
- ritardo di polling
- se il nodo principale (master) si guasta, l’intero canale resta inattivo
Protocollo token-passing Un messaggio di controllo circola tra i nodi seguendo un ordine preciso e prefissato. Messaggio di controllo (token). In particolare:
- Decentralizzato
- altamente efficiente
- il guasto di un nodo può mettere fuori uso l’intero canale
Indirizzi MAC
Sono indirizzi composti da 6 byte e sono associati alla scheda di rete. Sono univoci. Durante l’incapsulamento del datagramma, nell’intestazione ci sono due indirizzi MAC del mittente e del destinatario.
Ogni nodo ha il suo indirizzo MAC.
Esempio
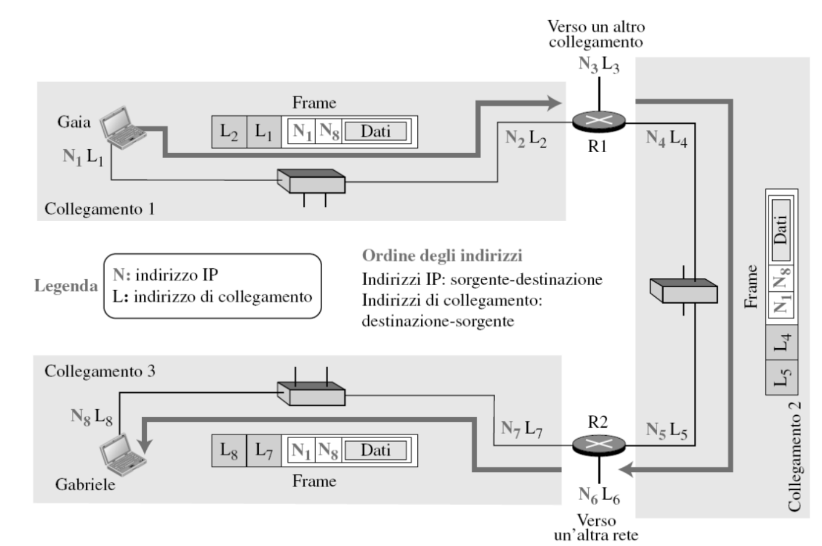
Abbiamo una sorgente e una destinazione. Il frame generato dall’orifine passa per due router. Il frame parte dall’indirizzo IP
CDMA Code division multiple access
Assumiamo di avere 4 stazioni connesse sullo stesso canale I dati spediti sono d1, d2, d3, d4, i codici assegnati c1, c2, c3, c4 Ogni stazione “moltiplica” i propri dati per il proprio codice e trasmette
Se moltiplichiamo ogni codice per un altro otteniamo 0 Se moltiplichiamo ogni codice per se stesso otteniamo il numero delle stazioni
Rappresentazione
Generazione sequenze di chip
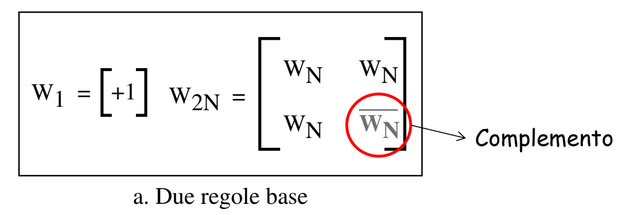
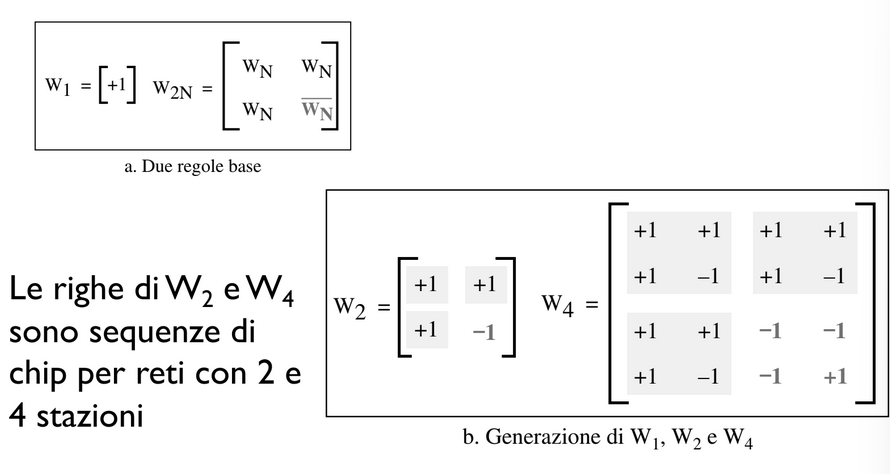
Viene utilizzata la tabella di Walsh (matrice quadrata) in cui ogni riga è una sequenza di chip.
indica una sequenza con un chip solo e può assumere valore +1 o -1 e conoscendo possiamo creare in questo modo:
Protocolli MAC
Bluetooth
E’ una tecnologia LAN wireless progettata per connettere dispositivi con diverse funzioni e diverse capacità. Ha un raggio trasmissivo di
E’ una rete ad hoc, infatti si forma spontaneamente senza aiuto di alcuna stazione base.
Bluetooth definisce 2 tipi di reti:
- Piconet: rete composta al massimo di 8 dispositivi. 1 stazione primaria e 8 secondarie che si sintonizzano con la primaria.
- Scatternet: combinazione di Piconet
Dispositivo Bluetooth Trasmettitore radio a breve portata Rate 1 Mbps Ampiezza di banda: 2,4 GHz
RFID Radio Frequency Identification
Vengono utilizzati per identificare degli oggetti tramite dei RF tag. Il reader ha delle antenne con la quale riceve la richiesta per ottenere gli ID.
Sicurezza delle reti LAN
Definizione di attacco
E’ un insieme di azioni che cerca di compromettere
- Integrità
- Confidenzialità
- Disponibilità di una risorsa
Riservatezza o confidenzialità solo mittente e destinatario (che devono essere autenticati) devono essere in grado di comprendere il contenuto del messaggio che deve rimanere segreto
Integrità il contenuto della comunicazione non deve essere alterato
Disponibilità Utenti legittimi devono poter usare i servizi di rete
Fasi di uno scenario di intrusione
- Scansione della rete: in questa fase si mira a recuperare più informazioni possibili sulla rete obiettivo (Network Mapping)
- Identificazione delle vulnerabilità: scansione dei singoli host e port scanning
- Attacco: vengono sfruttate vulnerabilità scoperte nella fase precedente, creando un punto di appoggio per un accesso futuro
- Espansione dell’attacco: l’intruso accede nuovamente al sistema per rubare dati confidenziali, cancellando file, mettendo fuori uso il sistema
Network mapping
Metodo per il recupero di informazioni sulla rete obiettivo, al fine di tracciare una mappa dei sistemi connessi e individuarne le vulnerabilità Per essere effettivo deve aggirare le regole adottate dai firewall (e progredire con il loro aggiornamento)
Storicamente basato su ping, adotta meccanismi molto sottili per introdursi in una rete e ottenere un risultato analogo
Obiettivo: ottenere in qualche modo una risposta dalle macchine sotto
Si suddividono in:
- Metodi basati su richiesta valida
- Metodi basati su richiesta non valida
Classificazione attacchi
- Sniffing: spiare la conversazione
- Spoofing: Impersonare un altro soggetto
- hijacking: Dirottare una sessione in corso
- Denial of service: Mettere fuori uso alcuni servizi
Classificazione malware
- Trojan: parte nascosta di un file utile.
- Virus: L’infezione proviene da un oggetto ricevuto (attachment di e-mail), e mandato in esecuzione
- Auto-replicante: si propaga da solo ad altri host e utenti
- Worm: L’infezione proviene da un oggetto passivamente ricevuto che si auto-esegue
Contromisure
- Antivirus
- Firewall
- Intrusion detection syestem
- Crittografia
Antivirus Software atto a rilevare ed eliminare programmi dolosi. Viene installato sui singoli host per cui agisce localmente all’host. Metodi:
- Esamina i dati interni al computer per rilevare presenza di programmi dolosi noti
- Analizza il comportamento dei vari programmi alla ricerca di istruzioni sospette perché tipiche del comportamento dei virus
Deve essere sempre aggiornato con la creazione di nuovi attacchi (sempre un passo indietro agli attacchi).
Firewall Installato sul punto di ingresso della rete che è un’interfaccia tra ciò che è fuori e dentro. Tutto ciò che passa viene analizzato dal firewall e in caso di rilevazione di qualcosa di anomalo, viene bloccato.
Funzionamento firewall
Tre tipi di firewall:
- A filtraggio dei pacchetti
- A filtraggio dei pacchetti con memoria dello stato
- A livello di applicazione (gateway)
Filtraggio dei pacchetti Una rete privata è collegata a Internet mediante un router. Il router è responsabile del filtraggio dei pacchetti e determina quali pacchetti devono essere bloccati o quali possono passare in base a:
- Indirizzo IP sorgente o destinazione
- Porte sorgente e destinazione TCP o UDP
- Tipo di messaggio ICMP
- Bit TCP SYN o ACK